
High-throughput data pipelines are the backbone of modern bioinformatics. But as datasets grow larger and analyses scale, traditional data management approaches are hitting a wall. Slow I/O, costly infrastructure, and operational overhead are persistent pain points for teams trying to run complex workflows efficiently in the cloud.
Fusion is the cloud-native file system designed and optimized for Nextflow pipelines that removes these barriers. It simplifies infrastructure, enhances performance, and cuts costs, making it easier for bioinformaticians to develop, maintain, and scale pipeline code. With major enhancements since its initial release (including NVMe-aware caching, zero-configuration setup, and seamless spot instance continuity), Fusion continues to empower teams to run pipelines faster and more efficiently across any cloud, with reduced overhead and greater control.
Discover FusionStorage is the bottleneck
Running pipelines in the cloud often means balancing performance, cost, and reliability. While object storage is affordable and scalable, it lacks the POSIX interface required by many bioinformatics tools. As a result, most tasks must copy data from S3 into local storage, perform processing, then copy outputs back: an inefficient, error-prone loop that adds significant overhead. In addition, data is often duplicated in storage—further inflating storage costs and complicating data management.
Alternatively, shared file systems like FSx for Lustre or EFS add complexity, require manual provisioning, and are expensive, especially across cloud availability zones.
Fusion: A smarter file system for Nextflow
Fusion solves this by offering a lightweight, POSIX-compliant file system layer optimized for Nextflow pipelines. It enables direct, high-performance access to Amazon S3, Google Cloud Storage, and Azure Blob Storage — without copying files or provisioning extra infrastructure.
5 Key Benefits of Fusion
- Breakthrough Pipeline Performance: Fusion accelerates pipeline throughput by up to 2.2x compared to S3-based execution by reducing redundant file I/O and leveraging high-speed NVMe storage when available.
- Cost Efficiency at Scale: Fusion delivers performance comparable to FSx for Lustre but at a fraction of the cost on the most commonly used bioinformatics pipelines.
- Spot Resiliency: Snapshots is a Fusion extension that makes it possible to capture the execution state of interrupted tasks, allowing pipelines to resume seamlessly after spot instance terminations — removing costly retries and resulting in more efficient compute time.
- Zero maintenance: Fusion is a thin layer on top of cloud vendors object storage system, and does not require any extra service or infrastructure to be deployed. It is automatically provisioned inside your pipeline containers via the Wave containerization service, eliminating the need for custom AMIs, convoluted deployment scripts, or workflow code changes.
- Multi-Cloud and Multi-Architecture: Now supporting ARM (Graviton) and x86, Fusion Snapshots and the Fusion driver run reliably across clouds and architectures — giving you flexibility and performance.
Hear from our customers: With Fusion, Bio-Rad Laboratories were able to streamline their infrastructure setup, reduce time-to-results by 24%, and cut cloud expenditure by 20%. Read the case study to find out more.

What’s new in Fusion
Fusion has continued to evolve since its initial release, with powerful new features that improve both performance and flexibility for production-scale workloads. New features include:
- →Fusion Snapshots: Persist task execution state to S3 on spot instance interruption, enabling restart-free recovery.
- →ARM support: Full compatibility with Graviton-based instance types for optimized cost-performance.
- →Expanded cloud support: Fusion now runs on AWS, Google Cloud, and Azure with minimal configuration.
- →Improved caching and pre-fetching: Fusion uses predictive caching and aggressive local storage optimization to dramatically speed up repeated data access across tasks.
- →Improved efficiency handling small files: While Fusion has been designed to improve the throughput when working on large dataset, there are use cases in which pipelines need to handle many small files. Fusion 2.5 provides significant improvements also for this scenario.
These enhancements make Fusion an even more powerful option for resilient, high-performance pipeline execution, regardless of scale or environment.
Benchmarking: Fusion vs. S3 and FSx
We benchmarked Fusion against other storage approaches using nf-core/rnaseq (version 3.15.1) and nf-core/sarek (version 3.5.1) across S3, FSx (FSx with Lustre with Scratch SSD) and Fusion.
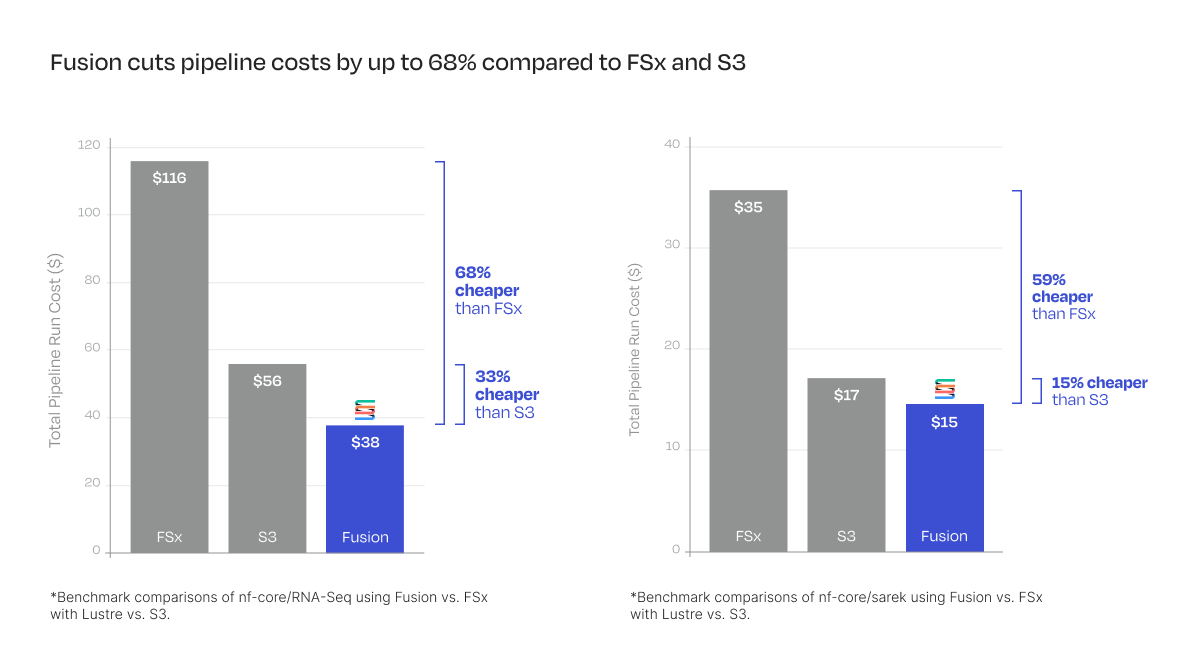
Cost-Efficiency: Fusion cuts pipeline costs by up to 68%
Fusion reduced the total run cost of running the test_full profile of nf-core/rnaseq by 68% versus FSx and 33% versus S3. Similarly, Fusion reduced the cost of running nf-core/sarek by 59% compared to FSx and 15% compared to S3. This substantial reduction in cost means that users running data-intensive pipelines can scale up their workflows without proportionally scaling up cloud expenditure.
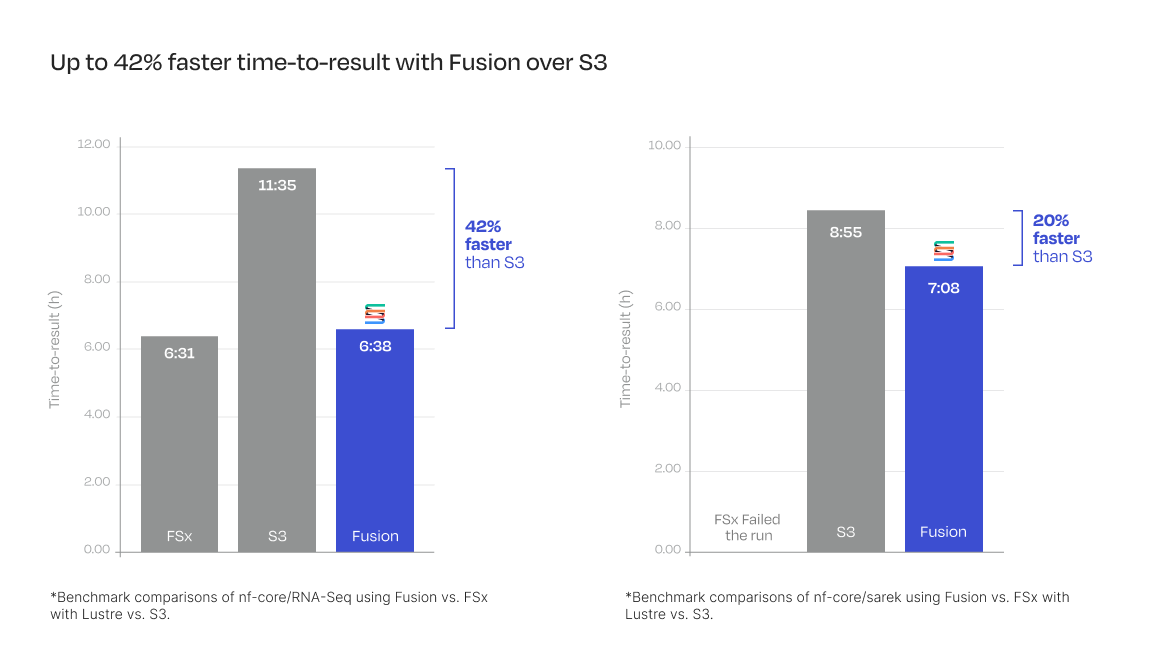
Performance: Fusion achieves up to 42% faster analysis
Fusion delivers breakthrough performance across genomics workflows. For RNASeq analysis, Fusion matched FSx's speed while running 42% faster than S3. For Sarek analysis, Fusion outperformed S3 by 20% and proved more reliable than FSx, which failed due to spot instance reclaims. This enhanced performance translates to faster iteration cycles, enabling researchers to accelerate discovery and get actionable insights more quickly.
Reliability: Fusion enhances reliability on Spot
An additional benefit of using Fusion is Fusion snapshots, which will prevent tasks from failing and re-running due to spot reclamations. In our tests on eu-west-1, about 7% of tasks failed due to spot reclamation events, which can lead to pipelines failing and needing to be resumed or in the worst case completely rerun. By preserving task data through snapshots, Fusion mitigates these interruptions, improving overall pipeline resilience and reducing manual intervention.
Using Fusion is easy
To enable Fusion in your Nextflow pipeline, simply enable the Fusion and Snapshots settings when creating the Compute environment is Seqera Platform:
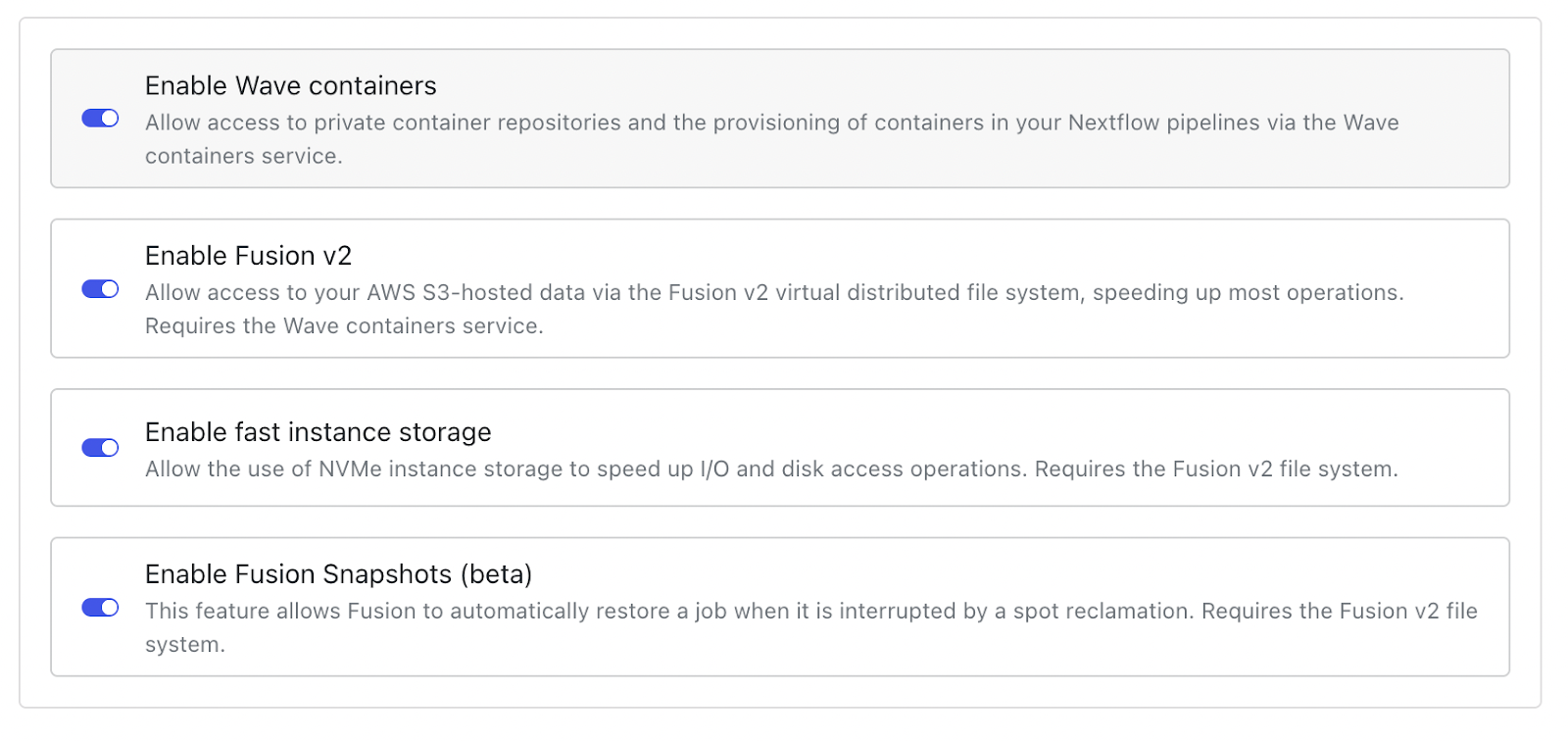
That’s it. Fusion is automatically provisioned with your containers, no custom images or installations needed.
Conclusion
Fusion is more than a file system — it’s a cloud-native data acceleration layer purpose-built for Nextflow. It delivers breakthrough pipeline performance, slashes compute and storage costs, and simplifies everything from deployment to resiliency across clouds. Whether you’re building high-throughput genomics pipelines or scaling across multiple clouds and architectures, Fusion lets you analyze data-in-place without sacrificing speed, reliability, or cost.