
Introduction
While solutions such as s3fs-fuse and Goofys that present a POSIX-like file system interface over object storage aren’t new, they’ve become a hot topic in Nextflow circles. In October 2022, Seqera unveiled the Fusion file system, a distributed lightweight file system for cloud-native data pipelines. This was followed by the AWS announcement of Mountpoint for Amazon S3 in June of 2023, a new file client designed specifically for Amazon S3.
In this article, we explain the differences between Mountpoint for Amazon S3 and Fusion, present some internal benchmarks we’ve run at Seqera, and offer recommendations about what file system should be used where.
Nextflow and Object Storage – what’s the deal?
Amazon S3 and similar object stores from other cloud providers are excellent solutions for many bioinformatics workloads. They are fast, inexpensive, and can scale essentially without limit. The downside is that most bioinformatics tools expect to interact with a Linux/POSIX file system.
To address this limitation, when running with Amazon S3, the default behavior in Nextflow is to automatically copy data required by each task from S3 to storage local to an EC2 instance where it is accessible to containerized tasks.1 The tool running inside the container then reads and processes the data as normal, and output files are copied back to S3. This “two-step” approach is illustrated below. While this is handled transparently by Nextflow, the problem is that significant time is wasted shuttling large files to and from S3.2
A more straightforward solution is to use a file system interface over S3, as shown:
Until recently, this approach had been impractical. Solutions such as s3fs-fuse were simply not up to the job ⎯ especially when dealing with multiple clients accessing large files in the same bucket. The availability of new solutions, such as Mountpoint for S3 and Fusion, is causing some Nextflow users to re-evaluate how they handle data in S3 environments.
About Mountpoint for Amazon S3
Mountpoint for Amazon S3 is an open-source file client that makes it easy for Linux-based applications to connect to Amazon S3 buckets. Mountpoint is designed for large-scale applications that read and write large amounts of data in parallel. Mountpoint doesn’t implement a full POSIX interface, but it supports most common file operations. It also performs significantly better than s3fs-fuse, offering ~6-8x the performance of s3fs when reading and writing sequential files as measured using the open-source FIO benchmark.3
Mountpoint is simple to install and configure. Once the client is installed and IAM credentials are entered in the ~/.aws/config file (or appropriate AWS environment variables), users can simply mount their bucket as shown and begin performing file system operations as shown:
About Fusion file system
Fusion file system is a distributed, lightweight file system for cloud-native pipelines. It is similar to s3fs-fuse and Mountpoint for S3 in that it provides a file system interface over S3. However, it is not intended as a general-purpose solution. Fusion is purpose-built to provide efficient access to S3 buckets from containerized Nextflow tasks.
Fusion is more than just another FUSE implementation. Unlike Mountpoint, which needs to be installed and configured before use, Fusion is deployed automatically into containerized tasks using the Wave container service and requires "zero configuration".
For Nextflow users, Fusion has several advantages.
- →Fusion is optimized for Nextflow pipelines
- →It is designed for single job execution and runs in the job container
- →Fusion supports pre-fetching, parallel download, async parallel upload
- →It supports file links over object storage
- →Eases data transfer pressures on the Nextflow driver app
- →Avoids the need for custom AMIs to run Nextflow on AWS Batch
Users can simply add the following lines to their nextflow.config file. Since Nextflow pipelines are typically run from a code repo such as GitHub, this is typically done once, and pipeline users don’t need to worry about Fusion after it is configured.
With Fusion and Wave enabled in the configuration file, users can simply run pipelines using an S3 bucket as a working directory:
Some key differences between Mountpoint for AWS and Fusion are shown below:
| Mountpoint for AWS | Fusion | |
|---|---|---|
| Installation method | User-installable | Deployed via the Wave container service |
| Usage | General purpose | Designed for Nextflow |
| Object stores supported | S3 only | S3, Google Storage, Azure BLOB Storage |
| Client-side caching | limited | aggressive |
| Typical deployment | Single client per host/VM | Single client per container |
| Predictive download | No | Yes |
| Asynchronous writes | No | Yes |
| Configuration effort | Moderate | Minimal |
| Optimized for large files | No | Yes |
| Support for symbolic links | No | Yes |
Comparing performance
To compare Mountpoint for S3 and Fusion perform, we conducted a benchmark using the open-source FIO benchmark. Details and source code of our benchmark are provided at https://github.com/seqeralabs/fusion-vs-mountpoint-benchmark.
Rather than testing with a 4 GB data file (used to compare s3fs-fuse and Mountpoint for S3), we wanted to test at a scale more representative of a production-scale pipeline. We tested sequential and random read-and-write performance for small and large files (5 MB and 100 GB, respectively).
We ran a variety of FIO read and write tests for each file system client. Readers can find the job file associated with each test and the overall results for each file system in the benchmark code repository. The results of six representative tests are presented below. We used a logarithmic scale to make the results easier to interpret.
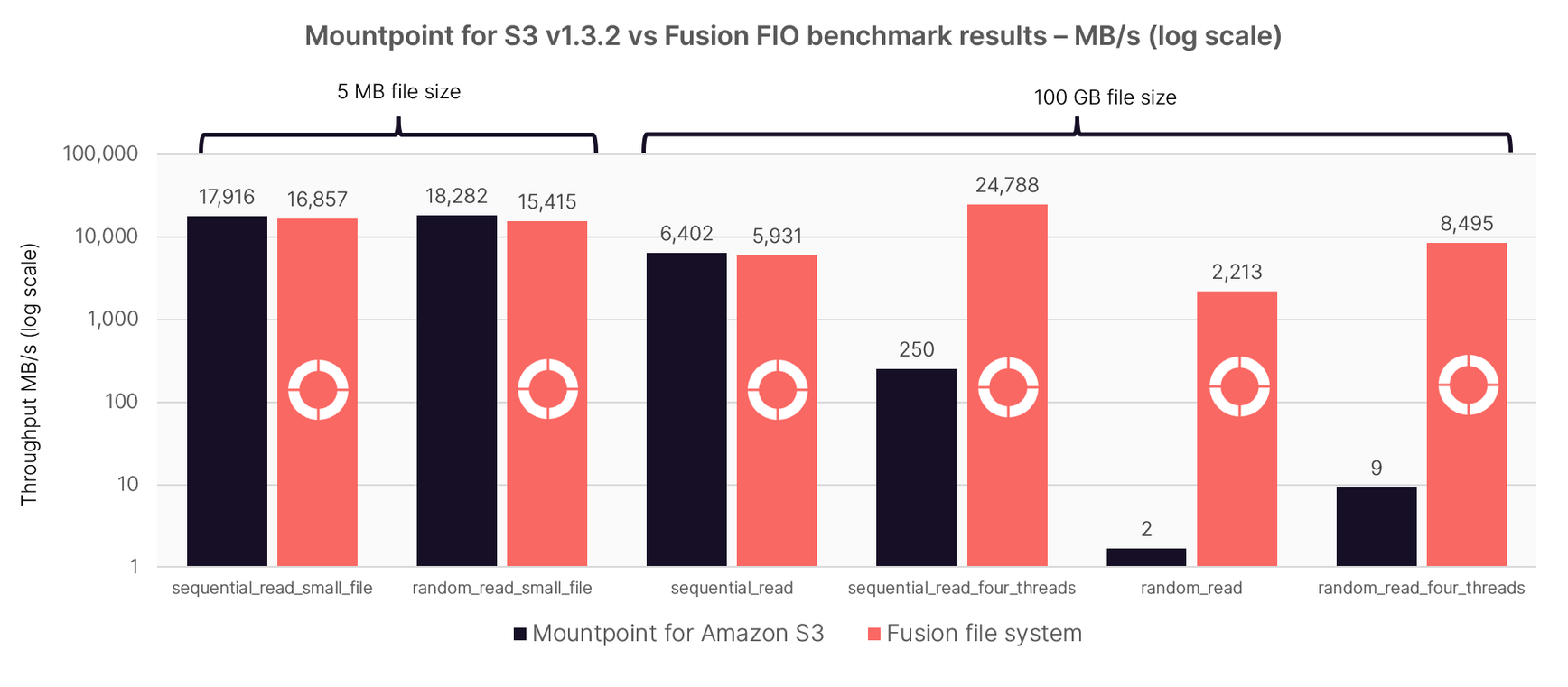
While Mountpoint for S3 and Fusion deliver similar performance for small files, the differences are dramatic when handling very large files typical of large Nextflow pipelines. Random reads of 100 GB files with Fusion as measured by the FIO benchmark were up to ~1,300 times faster than AWS Mountpoint.
Understanding Fusion’s performance advantage
These performance differences clearly require an explanation. The major difference between Mountpoint for S3 and Fusion, is that Fusion aggressively caches files on local storage. Both solutions get excellent results for small files because most requests are served directly from the kernel page cache. However, as files become large, the differences due to local caching dominate the results.
While this may seem like an unfair comparison, bioinformatics pipelines frequently reference the same large reference genomes hundreds of times from within different containerized tasks. As a result, pipelines benefit enormously from this type of caching. Mountpoint for S3 was simply not designed to address this type of problem. Production pipelines also benefit from Fusion’s support for symbolic links. Fusion caches the files associated with process output glob patterns and makes them available to downstream processes via symlinks, avoiding the need to maintain multiple physical copies of data. This results in pipelines running with Fusion having a smaller footprint on Amazon S3 resulting in lower storage costs.
Fusion has built-in garbage collection that evicts old cache entries on disk, so local storage can be much smaller than the actual needs of a large pipeline. However, production-scale pipelines will benefit from large amounts of local storage to act as a cache.
The recommended setup for maximum performance with AWS Batch is to mount an NVMe disk as the temporary folder and run the pipeline with the scratch directive set to false to avoid stage-out transfer time. You can accomplish this by adding the following lines to your Nextflow config file:
When should I use Mountpoint for S3 vs. Fusion?
Mountpoint is a good choice for general-purpose data access over S3 that does not require data-intensive I/O operations.
For Nextflow and Seqera Platform users, Fusion is usually the best solution because it is optimised for Nextflow data pipelines that need to operate with large data files common in genomics and life-science workloads. Enabling Fusion is simply a matter of sliding a few toggles in the Seqera compute environment settings and NVMe-capable cloud instances can be configured automatically.
Also, for staging data and inspecting intermediate results, users can use the built-in Data Explorer in the Seqera Platform to manage the contents of S3 buckets. This makes additional S3-compatible file clients redundant.
Learning more
To learn more about Fusion file system, download our whitepaper, Breakthrough performance and cost-efficiency with the new Fusion file system.
---
1 Normally, EBS storage is recommended for this purpose. In practice, datasets are often too large to fit in a cloud instance’s ephemeral storage, so Nextflow pipelines usually run on AWS cloud instances with EBS auto-scale enabled.
2 It is worth noting that this challenge of shuttling data back and forth is not unique to object storage. In clustered NFS and Lustre environments, a common practice is to copy data to local scratch storage for processing to avoid multiple clients overwhelming a shared file system with simultaneous reads and writes. Nextflow provides a scratch directive that controls this behavior.
3 A comparative analysis of Mountpoint for S3, S3FS, and Goofys, September 2023
4 A major difference between Fusion and Mountpoint for Amazon S3 is that Fusion is tightly integrated with Nextflow and has visibility to the Nextflow pipeline data channels at runtime. Fusion can use this information to proactively download and cache referenced files before they are required during execution.
5 Fusion sessions persist only for the life of the container implementing a task. Before containers terminate, they ensure that local pages are persisted to S3 storage. This allows Fusion writes to be asynchronous (non-blocking). Fusion can consider the write complete as soon as a write is committed to the local cache. If a container fails or is preempted before a write is committed from the local cache to S3, Nextflow simply reschedules the task.