
At the recent Nextflow Summit, during his talk on the modern biotech stack, Seqera co-founder and CEO Evan Floden described important new Seqera platform features aimed at resource optimization. Among these was support for AWS Fargate — a serverless pay-as-you-go compute engine in the AWS cloud that can be used as an alternative to Amazon EC2.
This article looks at Fargate support in the Seqera platform and explains when and how to use it. It also shows how Fargate can speed up pipeline launch, thereby increasing efficiency and productivity in many AWS cloud environments.
What’s the issue?
AWS Batch is an excellent solution for running pipelines in the cloud. Users can easily deploy compute environments, scale out infrastructure, and reduce costs by paying for capacity only when needed. Seqera Forge makes using AWS Batch especially easy by fully automating the configuration and deployment of the batch service with user-provided AWS credentials.
The problem is that batch startup times can be significant. To manage costs, most Seqera users set Min CPUs to zero (the default) when setting up compute environments. This means that each time a new pipeline is submitted to the head queue, the batch service needs to start an EC2 instance to support execution of a containerized Nextflow pipeline.1
Starting the required EC2 instances can take several minutes. For short-running pipelines, the time required to deploy the underlying batch resources can often exceed the pipeline runtime! This is where Fargate comes in.
AWS Fargate
AWS Fargate is a serverless compute engine in the AWS cloud. It is compatible with both Amazon ECS (used by AWS Batch) and Amazon EKS. Users specify the compute and memory resources required, and they can launch any OCI-compliant container in Fargate and pay for only the resources used.
Since December of 2000, AWS has supported Fargate as a serverless alternative to EC2 in AWS Batch. The main advantage of Fargate is its simplicity. Users don’t need to worry about details such as EC2 instance types, AMIs, OS versions, or patches. They can simply request a serverless execution environment with a specific amount of CPU and memory, and AWS looks after managing the underlying resources.
Seqera Platform support for Fargate
As of Seqera Cloud 23.2, users can elect to have Seqera Forge auto-configure AWS Batch to use Fargate for the batch compute environment supporting the Nextflow head job.
To enable Fargate, select the Enable Fargate for head job toggle as shown when using Seqera Forge to deploy your AWS Batch compute environment:
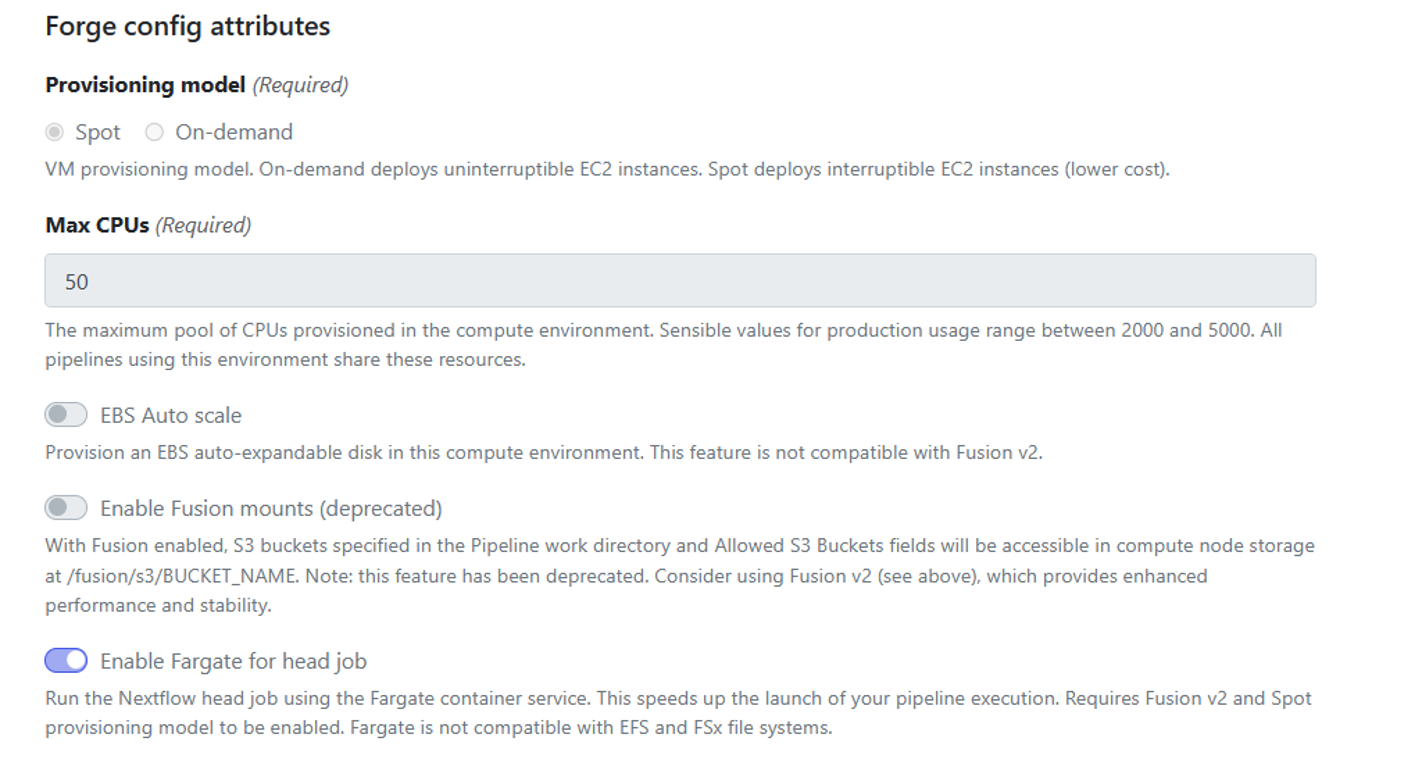
Fargate support requires that Wave, Fusion file system, and Spot provisioning also be enabled in the compute environment setup. Fargate is not supported with Amazon EFS or Amazon FSx for Lustre. If you prefer to use these file systems, you should continue to use the default Amazon EC2 environment.
While Fargate is presently supported for the Nextflow head job, it is not supported for task executions. Fargate is less useful for tasks because users often require particular Amazon Machine Images (AMIs) or specialized instance types with GPUs or other specialized resources. Presently, Fargate supports neither of these capabilities. Fargate holds huge promise for tasks as well however, so we continue to monitor developments and evaluate how Fargate might be used with Nextflow tasks in a future release.
Putting Fargate to the test
To measure the impact of Fargate on startup time for the head job, we provisioned two similar AWS Batch compute environments using Seqera Forge, each with 50 vCPUs and access to the same shared S3 storage bucket. The first environment was configured to use Amazon EC2 (the default), and the second was configured to use AWS Fargate for the head job. Both environments requested Spot instances for Nextflow task execution.
To simulate a short-running pipeline, we selected a simple proof-of-concept rnaseq-nf pipeline and ran it three times from the Seqera launchpad using the EC2-based compute environment described above.
Measuring startup time
While Seqera provides rich statistics about pipeline execution, it starts gathering information only after the Nextflow pipeline is started. To understand how long it takes to provision the EC2 compute resources before the pipeline starts, it is better to monitor job execution from within the AWS Batch console or the CLI.
Using the same AWS account used for your Seqera compute environments, navigate to the AWS Console and select the Batch service. From the menu on the left, select Jobs to see current and previously run AWS Batch jobs.
Next, filter the list of jobs by selecting the head queue associated with the first EC2-based Seqera compute environment under Job queue as shown:
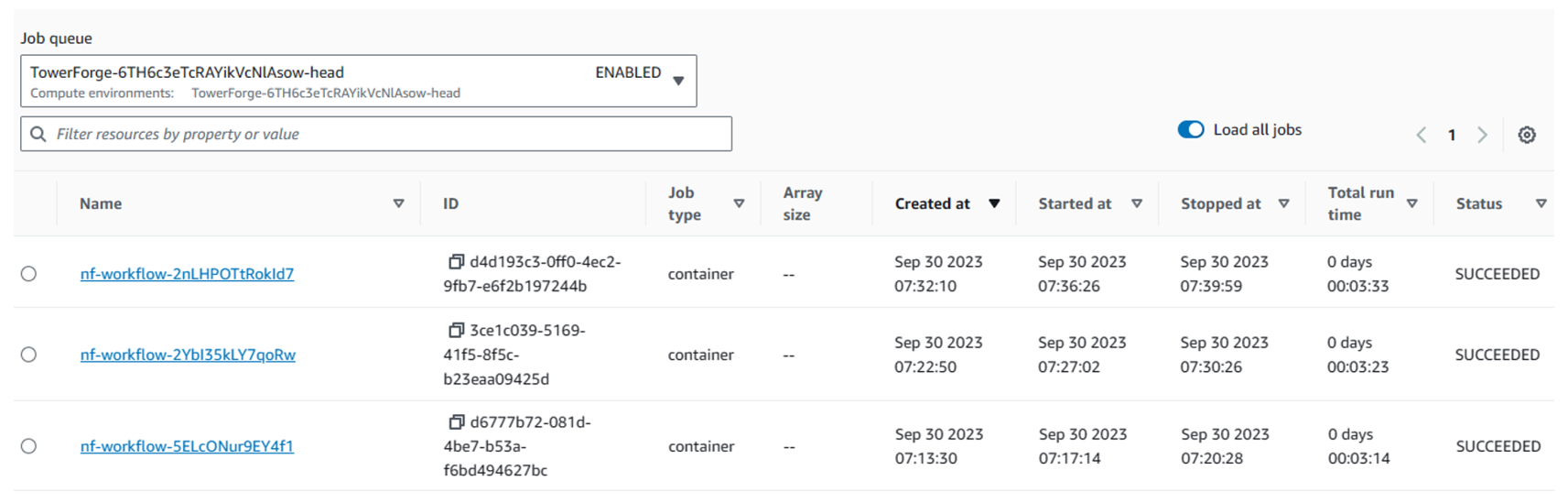
AWS Batch queues created by Seqera Forge start with the string “TowerForge” and end with either “head” or “work” depending on whether the queue supports the head job or the tasks comprising the pipeline.2
The AWS Batch Jobs view shows details about each instance of the rnaseq-nf pipeline we submitted above. Note that AWS Batch reports when the job was created vs. when it was started and stopped. The delay between creating and starting a job is a good proxy for the time it took AWS Batch to get the underlying compute resources (EC2 in this case) marshalled and ready for use.
Faster pipeline starts with Fargate
Next, we launched three additional instances of the rnaseq-nf pipeline using identical parameters to the second compute environment configured with Fargate enabled. We repeated the process above, measuring AWS Batch job statistics by filtering jobs submitted to the head queue associated with the Fargate compute environment.
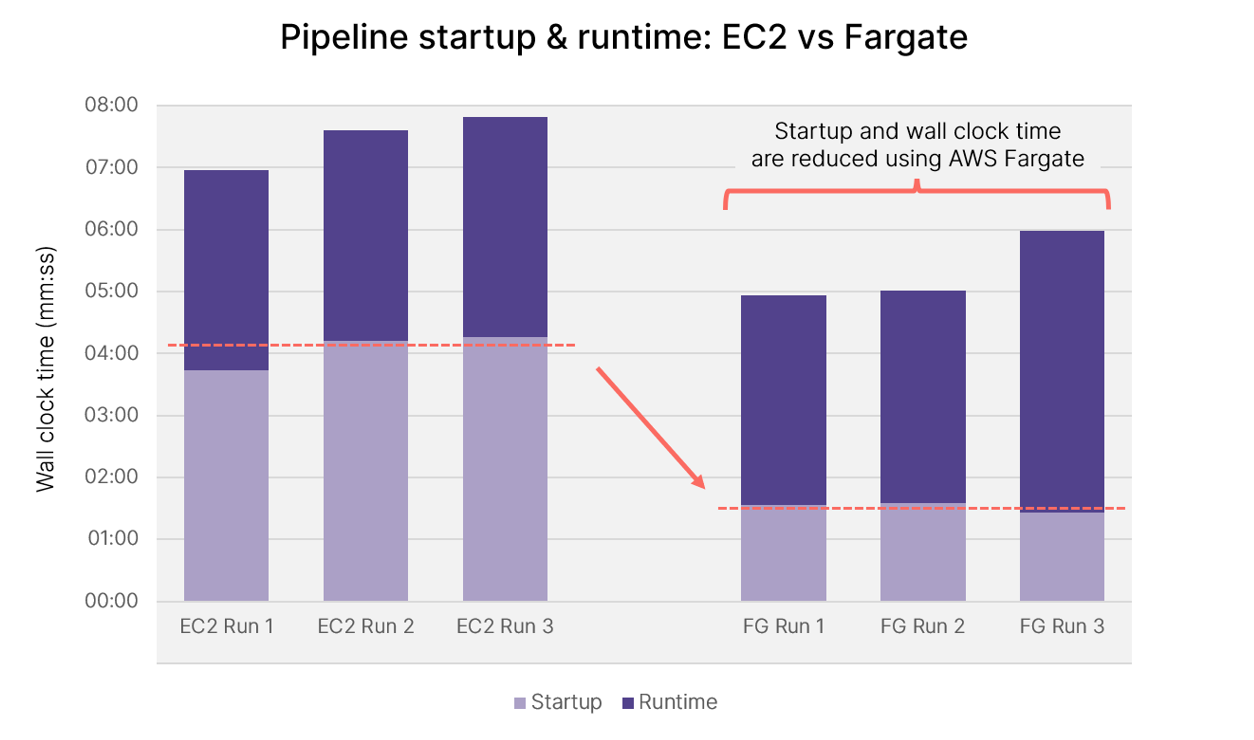
The results for all six runs (three on EC2 and three on Fargate) are tabulated below:
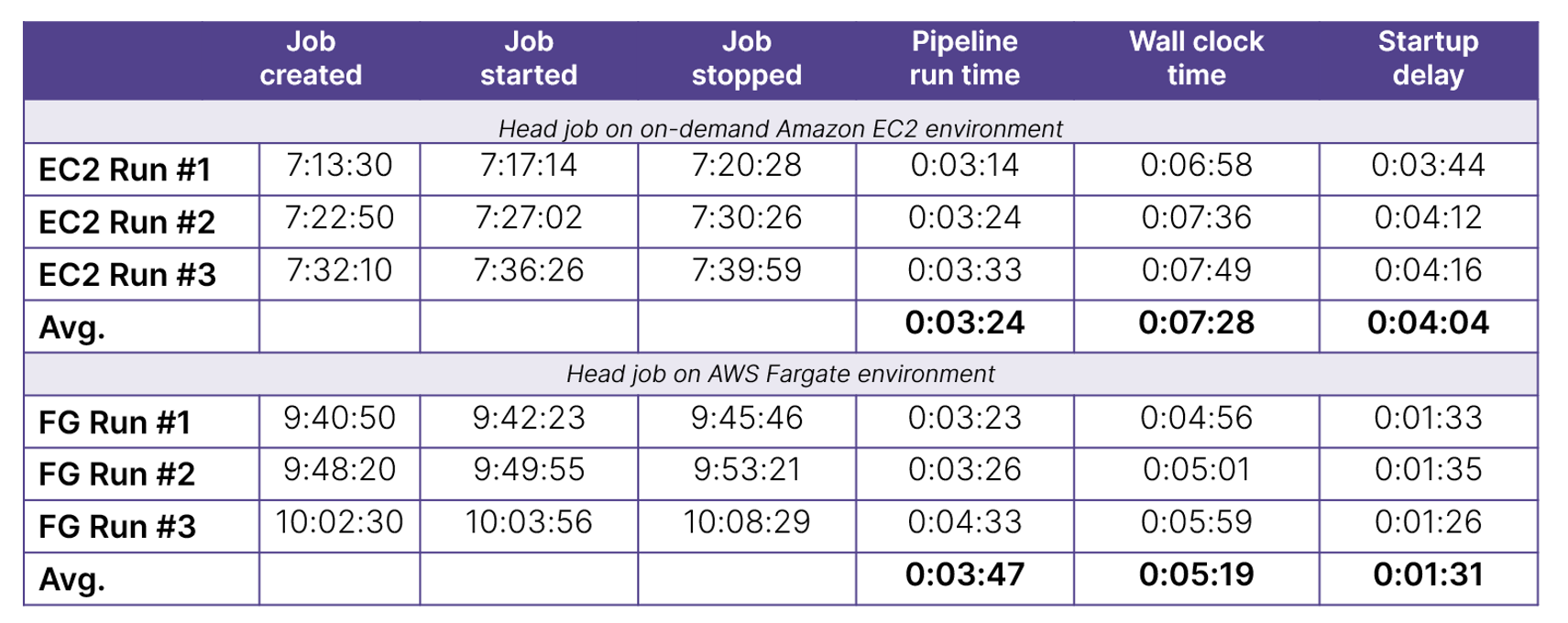
While there is some variability in startup and run times for each pipeline, on average, in the Fargate environment, the head job started in just 1:31 (91 seconds) vs. 4:04 (244 seconds) for the default EC2 on-demand environment.
The results are summarized in the graph below. On average across our sample runs, using Fargate reduced pipeline start times by 63% and total elapsed wall clock times by 29%!
What’s the bottom line?
If you’re running pipelines on AWS Batch with Seqera, selecting Fargate as the execution environment makes sense in most cases. While the impact will be most noticeable for short-running pipelines, saving a few minutes on each pipeline definitely helps!
Fargate is slightly more expensive than EC2 for equivalent resources, but the minor cost difference is offset by the fact that Fargate sizes resources precisely based on the CPU and memory requested for the head job.3
When using EC2, you pay for all the resources in the provisioned EC2 instance whether you use them or not. Cost impacts are negligible because costs for pipeline runs tend to be dominated by compute tasks and storage, and these are unaffected by the choice of the environment for the head job. You can expect to realize performance benefits and cost savings by using the Fusion file system, however.4
See the whitepaper breakthrough performance and cost-efficiency with the new Fusion filesystem
The only time you will not want to use Fargate are if you are using Amazon EFS or FSx for Lustre as a shared file system, or if you are unable to use the Fusion v2 file system. For example, your site may have a policy that disallows the use of the Wave container service, which is a prerequisite for Fusion file system. There may also be rare cases where you need control over the instance type or AMI associated with the Nextflow head job.
You can experiment with running your Nextflow pipelines on Fargate yourself by creating a free Seqera account at https://seqera.io
1 When Spot instances are selected (recommended), Seqera Forge automatically sets up separate AWS Batch compute environments and queues for the head job and Nextflow compute tasks. This configuration allows the head job to run using EC2 on demand resources (to avoid preemption) while the compute tasks run on lower-cost preemptible EC2 spot instances.
2 If you are confused about which AWS Batch queue maps to which compute environment in Seqera, you can inspect your compute environments using the Seqera interface. Seqera displays the names of the head queue and compute queue auto-provisioned by Seqera Forge for each compute environment. With the renaming of Tower to Seqera, AWS Batch queue names will likely be prefixed with Seqera in future.
3 See AWS Fargate pricing: Presently in US East region, on demand Fargate services are priced at $0.04048 per vCPU hour and an additional $0.004445 per GB hour. This means that an 8GB container with 1 vCPU costs $0.04048 + (8 \* $0.004445) = $0.07604/hr with Fargate vs. $0.0504/hr for an equivalent r6g.medium on demand EC2 instance.
4 See the whitepaper Breakthrough performance and cost-efficiency with the new Fusion filesystem. Fusion has been shown to improve pipeline throughput by up to 2.2x compared to Amazon S3 alone.