

Running AI workloads on Seqera: Maximizing computational resources with mixed GPU and CPU environments
Introduction
The unprecedented growth in AI adoption is reshaping how scientists approach complex problems, enabling faster and more accurate data analysis, drug discovery, and even clinical trials. This shift is largely driven by advancements in computational power, allowing researchers to tackle more complex tasks that were previously unmanageable.
While exciting, the rapid advancement of AI technologies presents challenges for researchers regarding the diverse computational needs of their workloads. GPU parallel workloads, mixed compute and hardware requirements, and the need for flexible development environments have become crucial to navigating this changing landscape.
GPU parallel workloads
AI tasks are inherently parallel, especially when dealing with large datasets and complex models. This parallelization can significantly speed up training times by enabling simultaneous execution of many computations. However, effectively utilizing GPU parallel workloads presents challenges, as workflows need to be designed to make the most of GPU capabilities. Tasks that involve heavy parallelization must ensure that resource allocation and data dependencies are managed appropriately to avoid bottlenecks and inefficiencies. Designing workflows that maximize GPU performance, while maintaining accuracy and consistency, is critical in optimizing AI model training and inference.
Compute and hardware requirements
In high-performance computing, some workflows demand significant computational power, while others require specialized hardware, like GPUs, for machine learning and AI tasks. Additionally, systems must be flexible enough to run across various configurations, from local machines to cloud environments. Yet not every task justifies the cost of a GPU instance. By adopting a “mixed” environment that mixes CPU and GPU instances, Seqera Platform users can keep costs in check while ensuring that resource-hungry tasks get the power they need.
Flexible developer environment
A flexible environment for development is essential for rapid prototyping and iteration of AI models in bioinformatics. Researchers need to be able to experiment with algorithms and configurations without infrastructure constraints. This flexibility necessitates a solution that enables quick deployment and modification of workflows, facilitating innovation and efficient model refinement.
Nextflow and Seqera: A solution for AI workloads
Nextflow is a powerful workflow management tool designed to streamline complex data analysis pipelines. Its capacity to efficiently handle mixed compute workloads makes it an ideal choice for AI tasks. This enables developers to work in a familiar environment while maintaining the flexibility required for AI workloads.
"Nextflow is built around the idea that Linux is the lingua franca of data science."
Containerization is a key advantage in managing these workloads; by encapsulating applications and their dependencies into containers, developers ensure consistent environments across various stages of development. This reduces the “it works on my machine” syndrome and promotes easier collaboration. With minimal overhead for each process, Nextflow is highly adaptable, allowing researchers to run workflows seamlessly across different computing environments.
Seqera further enhances these capabilities by streamlining resource management and optimizing the use of cloud services for on-demand GPU resource scaling. By using configuration rather than code for resource selection, developers can easily switch between different resource types, providing remarkable versatility. This separation of pipeline development from deployment not only enhances flexibility but also simplifies overall workflow management, allowing teams to adapt workflows without disruption.
Using AWS Batch to mount GPU devices inside containers
With Seqera
Batch Forge, available on Seqera Platform, streamlines the process of building custom infrastructure on AWS, GCP, and Azure. In this blog post, we’ve focused on AWS—the most mature platform in terms of configurable options.
AWS Batch overview
AWS Batch is a popular execution environment for Seqera Platform users. AWS Batch uses queues and compute environments (CEs):
- →Queues: First-in, first-out task collections that hold jobs awaiting execution.
- →Compute Environments (CEs): Groups of instance types that AWS Batch can allocate for tasks within a queue.
Seqera builds CEs through Batch Forge, allowing users to specify resources like CPUs, memory, and GPUs. Let’s explore how these settings work in a real-world scenario.
Deciding between on-demand and spot instances
When creating CEs, users must choose between two primary types of instances:
- →On-Demand Instances: Reliable but costly, these instances can be used for crucial jobs—like the Nextflow head job and Data Studios—that should not be interrupted.
- →Spot Instances: Cost-effective and potentially volatile, these are ideal for tasks that can be interrupted and resubmitted without affecting the overall workflow.
For Spot CEs, Batch Forge creates two distinct queues: one dedicated to head jobs (using the AWS Batch “optimal” instanceTypes) and the other for task workloads (using your specified instance types). Conversely, On-Demand CEs utilize a single queue for all jobs
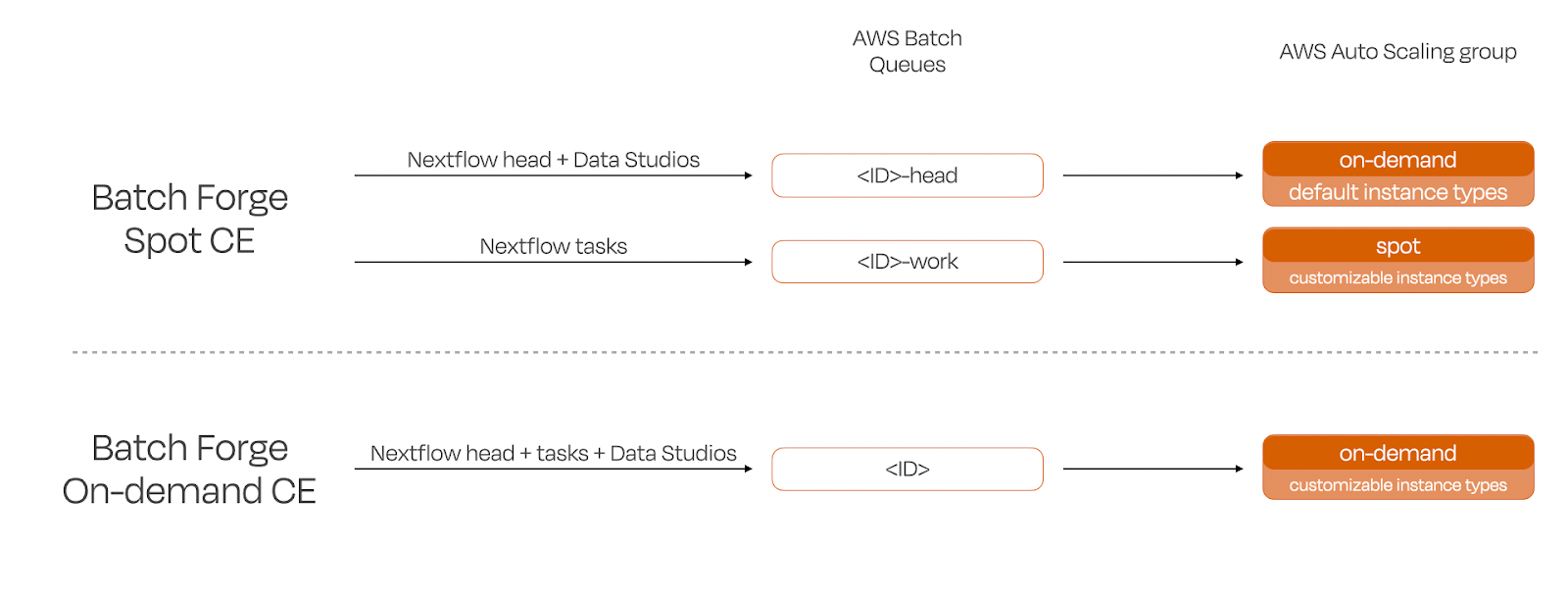
Figure 1. When using Batch Forge to create a Compute Environment (CE), you have the option of creating the CE using spot or on-demand instances. If a spot CE is created, all Nextflow tasks will be routed to the spot instances, but the Nextflow head and Data Studios jobs (interactive sessions with Jupyter, R IDE, or other IDEs) will need to run on uninterruptable on-demand instances. To accommodate both types, Batch Forge creates two queues for each Spot CE - a “-head” queue for Nextflow head and Data studios and a “-work” queue for Netflow tasks. An on-demand CE only requires a single queue.
Use case: A mixed GPU and CPU Environment
Consider a workflow with mixed CPU and GPU requirements. A GPU instance might be critical for deep learning tasks, while data preprocessing or smaller analytical steps can run on CPU instances. To enable this, you can direct the CPU and GPU jobs to distinct queues, or direct all jobs to a single queue that uses both hardware types:
- →Separate Queues:
- →GPU-Only CEs: Dedicated queues and environments with GPU-optimized instances for tasks requiring dedicated hardware.
- →CPU-Only CEs: Instances selected without GPU capability, perfect for general purpose computation.
- →Mixed Queue: Both CPU and GPU instances are selected in a single CE, perfect to seamlessly request GPUs using Nextflow’s “accelerator” directive.
💡Considerations for mixed environments
• Instance reusability: If multiple jobs require similar resources, AWS Batch may keep instances active for reuse, thus preventing unnecessary instance reinitializations.
• Automatic fallback for non-GPU tasks: If a CPU task arrives while a GPU instance has spare CPU capacity. AWS Batch will use that GPU instance to avoid spinning up an additional CPU-only instance, maximizing your cost efficiency.
Creating a queue that can accept all types of jobs requires less configuration, but can, in some cases, lead to unintended consequences, like a long-running CPU task tying up a GPU instance. If you would prefer to entirely avoid the possibility of non-GPU jobs running on GPU instances, creating separate queues would be advised.
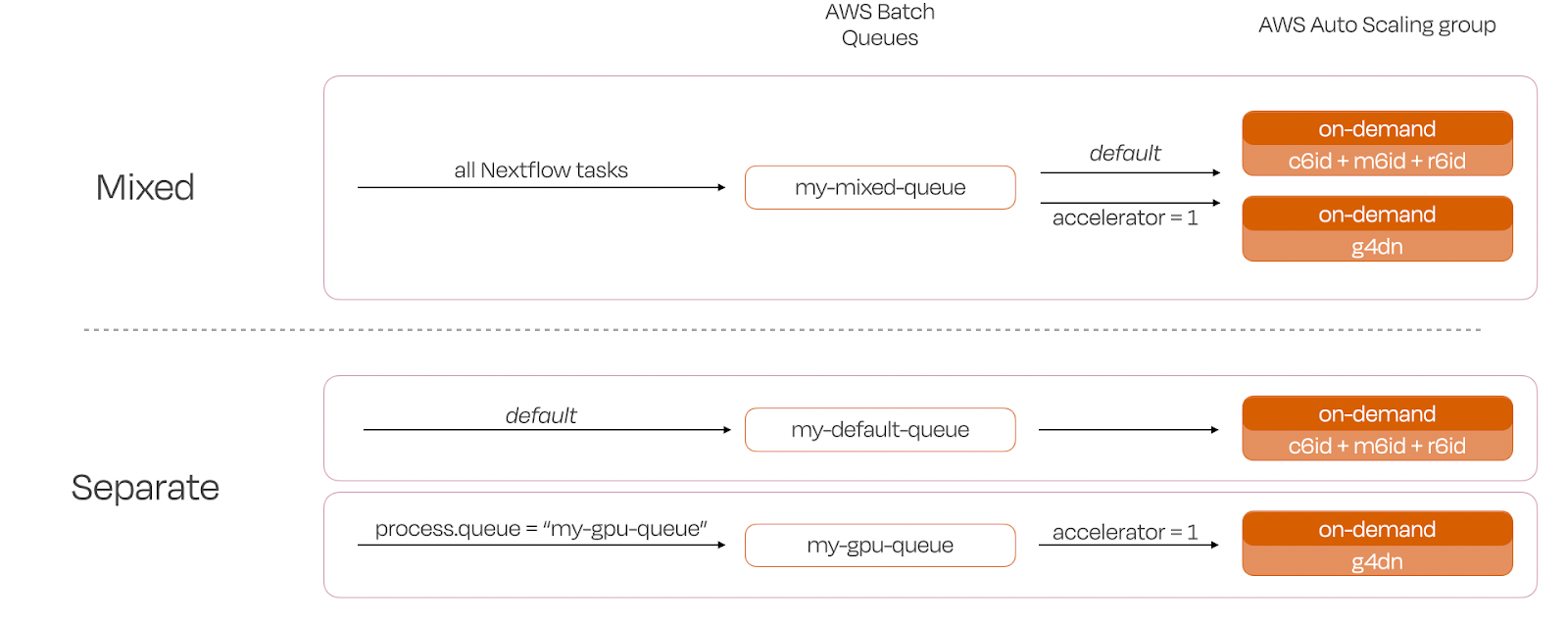
Figure 2. Illustration of GPU setup alternatives using on-demand Compute Environments. In “Mixed”, a single Seqera Platform CE is used for GPU and CPU tasks alike. GPU tasks are directed to the GPU instances via the accelerator directive. In "Separate", two Seqera Platform CEs are created. The job is submitted to the first CE and GPU-requiring tasks are directed to the GPU queue via the process.queue directive.
How to create a mixed environment with Batch Forge
Step 1: Create compute environments
- →Choose GPU-Optimized AMIs: In a hybrid CE, select the GPU-optimized Amazon Machine Image (AMI). This ensures all GPU hardware is supported and drivers are installed.
- →Specify CPU and GPU instance families according to your task requirements. For example: g4dn (GPU), and c6id, m6id, r6id (CPU)
Step 2: Direct workflows with Nextflow
Tasks that require GPU hardware need to be distinguished from other tasks. The “accelerator” directive (docs) flags processes that require GPU hardware. When using the AWS Batch executor, Nextflow will include a GPU request in the AWS Batch job definition.
For example, to attach the accelerator directive to a process named “RUN_ESMFOLD”
With the GPU request attached to the job definition, AWS Batch takes care of mounting the necessary GPU devices inside your containers, enabling seamless execution of your AI tasks. This approach not only reduces the complexity of resource management but also allows for scalability across different hardware environments.
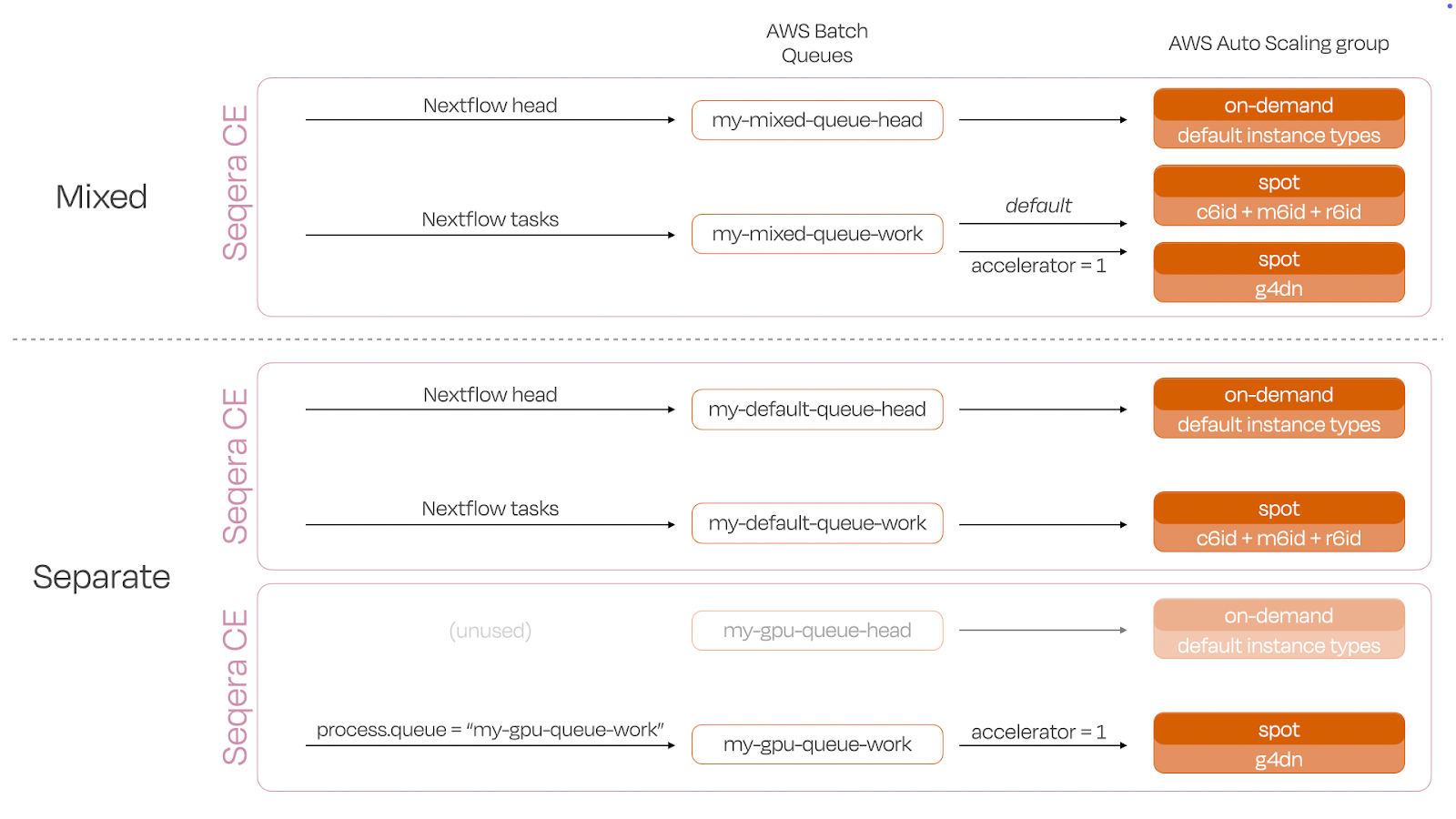
Figure 3. Illustration of GPU setup alternatives using spot Compute Environments. When a spot CE is created, Batch Forge creates two queues in each CE. In “Mixed”, a single Seqera Platform CE is used for GPU and CPU tasks alike. GPU tasks are directed to the GPU instances via the accelerator directive. In "Separate", two Seqera Platform CEs are created. The job is submitted to the first CE and GPU-requiring tasks are directed to the GPU queue via the process.queue directive.
How to set up separate queues
Step 1: Create two separate queues
- →For the GPU-only queue, select the GPU-Optimized AMIs.
- →Specify Instance Types: Pick instance families according to your task requirements. For example:
- →CPU-Only: c6id, m6id, r6id
- →GPU-Only: g4dn (or similar)
Step 2: Direct tasks to correct hardware via Nextflow configuration
Use Nextflow’s queue directive (docs) in your workflow script to direct tasks to specific queues based on their hardware needs. GPU-intensive tasks go to the GPU-only queue, while CPU-only tasks are routed to a standard CPU queue. To manage the number of jobs submitted to a single machine, use the accelerator directive for the GPU tasks:
How to set up Data Studios
Depending on the requirements of your downstream tasks, use either CE type to set up a Data Studio. Data Studio compute environments are necessarily on-demand to avoid spot reclamation. If you require GPUs for your interactive analysis, you can build either a GPU-only or mixed queue, but the CE will need to be an on-demand CE. During the setup, you can select the number of GPUs and CPUs you require:
Conclusion
Nextflow, integrated with Seqera, offers a powerful and flexible solution for AI workflows that involve mixed hardware requirements. Whether you’re conducting large-scale simulations, image processing, or data analysis, Batch Forge’s hybrid environments empower you to maximize efficiency and save costs. This combination provides a scalable, flexible computational environment that can adapt to the rapidly evolving demands of AI research and development.
Key benefits include:
- →Easy infrastructure setup: Deploy once on Seqera and apply it universally across projects. Combine CPU and GPU instances within a single environment, minimizing instance spin-ups and maximizing resource use.
- →Direct Tasks with Nextflow: Use Nextflow’s accelerator directive and queue settings to ensure tasks are allocated to the right resources.
- →Flexibility: Compatible with any software, not just pre-approved toolsets.
- →Cost efficiency: Save on expenses by automatically scaling down resources when not in use and configure all relatively short-lived tasks to use spot instances, helping to manage overall expenses without compromising your critical processes.
- →Development scaling: Ideal for iteration and development before full-scale deployment.
- →Seamless transition to production: Ideal for moving ML models from local development to the cloud, even if they don’t get deployed.
- →Future-proofed: Adaptable to future paradigms, custom hardware, and new tools.
Embrace the hybrid model, and let your compute resources work smarter!