
When it comes to running bioinformatics workflows in the cloud, infrastructure matters. Bioinformaticians have multiple choices, including cloud instance types, billing models, storage architectures, workflow managers, and provisioning tools. Researchers want to deploy infrastructure that yields the best performance at the lowest cost, but this is easier said than done. Workflows are often complex, cloud infrastructure usage is notoriously difficult to instrument and measure, and users need to grapple with complex, cloud-specific provisioning tools. Fortunately, there is a better way to deploy and run cloud pipelines to boost performance while simultaneously reducing cost.
Optimizing infrastructure delivers significant returns
Nextflow has emerged as a preferred orchestrator for bioinformatics pipelines for good reasons. It is portable, easy to use, provides rich container support, and enables reliable, reproducible pipeline execution with advanced data handling features. Nextflow is particularly well-suited to cloud because of its out-of-the-box integrations with leading cloud environments and storage architectures.
Diamond Age Data Science and AWS recently collaborated on a series of GATK benchmarks to explore how different instance types, billing models, and storage technologies impacted performance and cost. They ran a series of common GATK variant discovery and joint genotyping workflows on various compute environments on AWS. They chose Nextflow for these tests because of its ease of implementation and rich support for AWS Batch, AWS storage types, and spot instances. With built-in support for Amazon FSx for Lustre, Nextflow Tower provided an efficient and straightforward way to deploy high performance cloud infrastructure quickly.
While it seems counter-intuitive, choosing more expensive storage technologies can reduce costs. FSx for Lustre is nominally 40% more expensive per GiB than Elastic Block Storage (EBS)1. However, using FSx reduced total costs by up to 26%, depending on the compute instance2. It did this while simultaneously delivering performance gains of up to 2.7x. The use of Spot instances also dramatically reduced costs by up to 80% in some cases.
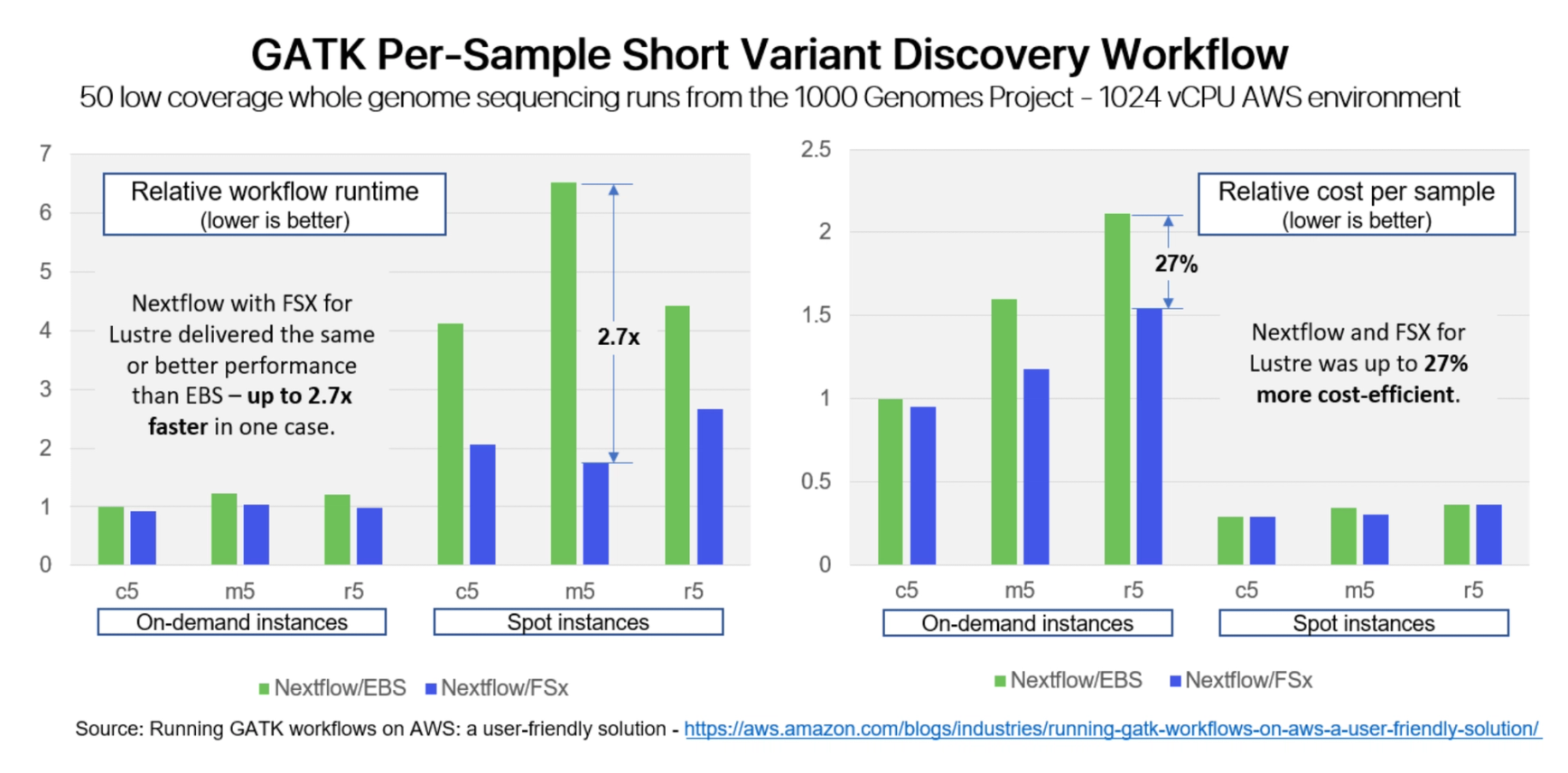
While results will vary by pipeline, there are several reasons for these improvements:
- →By persisting data in a shared FSx file system, there is no need to copy data back and forth between object storage and local block storage as instances come and go, resulting in significantly improved throughput.
- →With a high-throughput parallel file system, tasks spend less time waiting on I/O, resulting in better compute utilization, higher throughput, and lower cloud costs.
- →Finally, while FSx storage costs more, compute costs tend to dominate storage costs. Even minor improvements in throughput can drive significant financial savings – especially for more expensive instance types.
Existing solutions fall short
Deploying cloud infrastructure can be tedious and time consuming. While tools such as AWS Cloud Development Kit (CDK) and Azure Resource Manager (ARM) templates help, users still need to build and maintain custom scripts, learn domain-specific languages, and perform manual actions.
Provisioning tools are typically cloud-specific, complicating multi-cloud deployments and impeding pipeline portability. Even minor changes to infrastructure elements typically involve re-coding and testing – tasks that cost time and money. Also, once deployed, pipeline performance is hard to measure. Cloud monitoring tools can track resource utilization and total spending, but they lack visibility to individual workflow steps making it challenging to optimize infrastructure selection. Fortunately, Nextflow and Nextflow Tower make it dramatically easier to monitor workflows and deploy infrastructure optimally.
Taking the guesswork out of infrastructure
Rather than require users to develop cloud-specific provisioning scripts, Nextflow Tower fully automates the deployment of compute environments. A simple, intuitive Web UI enables non-specialists to quickly and consistently deploy infrastructure across all major clouds and on-prem workload managers.
Users can leverage a free hosted version of Tower at https://tower.nf or deploy Nextflow Tower Enterprise in their own environments for production pipelines. Nextflow Tower also provides a comprehensive API for monitoring and managing pipeline actions, compute environments, users, workflows, and more. The Tower Forge feature automatically manages cloud resources, dramatically simplifying the setup of cloud computing services like AWS Batch, Azure Batch and Google LifeSciences.
By using Nextflow Tower to manage compute environments, organizations can:
- →Deploy optimal storage infrastructure with the click of a mouse, including Amazon S3, FSx for Lustre, Amazon EFS, or auto-scaled EBS volumes.
- →Leverage low-cost spot instances, automatically scale resources on-demand, and dispose of compute instances when not used to avoid accidental overspending in the cloud.
- →Support multiple clouds and on-prem compute environments, stay portable, and avoid lock-in.
- →Focus on their science and results rather than becoming bogged down in cloud provisioning details.
Ready to get started?
Nextflow now supports the use of advanced and scalable file systems such as AWS FSx and Nextflow Tower makes it possible to deploy and configure complex cloud resources in a cost efficient manner. If you want to learn more about these technologies, visit https://nextflow.io/ or https://tower.nf. A Nextflow-optimized pipeline for the GATK4 short variant discovery workflow described above is available from Seqera Lab’s GitHub repo. A variety of curated Nextflow open source community pipelines are also available from nf-core.
Credits
Thanks to Michael DeRan, Chris Friedline, and Netsanet Gebremadhin from Diamond Age Data Science, and Jenna Lang and Lee Pang from AWS for their work on this benchmark.
References
- →1EBS published pricing was 0.000138 &/GB-hour vs 0.0001944 $/GB-hour for FSx for Lustre.
- →2See benchmark results from in the AWS blog: https://aws.amazon.com/blogs/industries/running-gatk-workflows-on-aws-a-user-friendly-solution/. Using on-demand C5 instances with FSx was 5% faster than the same instances with EBS storage for a per-sample short variant discovery workflow. Similarly, when using general-purpose r5 on-demand instances, FSx storage reduced total cloud costs by 27% vs EBS storage.