

The upcoming 25.10 release of Nextflow uses the AWS Java SDK v2, which brings a significant performance boost to pipelines running on Amazon S3. In this blog post, we will show how this new version of Nextflow improves S3 performance, both at the level of basic S3 operations and end-to-end workflow runs.
What’s Changed?
For years, Nextflow used the AWS Java SDK v1 for S3 interactions such as staging input data, writing intermediate results, and publishing outputs. While reliable, SDK v1 is synchronous by design, which can limit throughput for high-volume workloads.
The AWS Java SDK v2 (used in Nextflow 25.10) introduces an asynchronous S3 client built on the AWS Common Runtime (CRT). The CRT is a high-performance C library shared across all AWS SDKs which provides optimized implementations of common networking and cryptographic operations.
This foundation allows Nextflow 25.10 to perform S3 transfers more efficiently. It not only improves throughput for large datasets, but also optimizes resource usage, making it the recommended approach for high-performance S3 workloads.
Benchmarking S3 performance in Nextflow
We conducted a series of performance benchmarks comparing Nextflow 25.04 (which uses SDK v1) with a preview build of Nextflow 25.10 (which uses SDK v2).
Basic S3 Operations
In the first benchmark, we used the nextflow fs command to measure the performance of basic S3 operations in Nextflow:
- →Copy: copying files directly between S3 buckets
- →Download: downloading files from an S3 bucket to a local destination
- →Upload: uploading files from a local source to an S3 bucket
We performed each operation on the following synthetic datasets:
- →One: a single 50 GB file
- →Many: a collection of 50 files (1 GB each)
Finally, we repeated these cases across a range of compute-optimized (C5, C6, C7) EC2 instances:
- →
large(2 CPU / 4 GB) - →
xlarge(4 CPU / 8 GB) - →
2xlarge(8 CPU / 16 GB)
The following figures show the results for each operation.
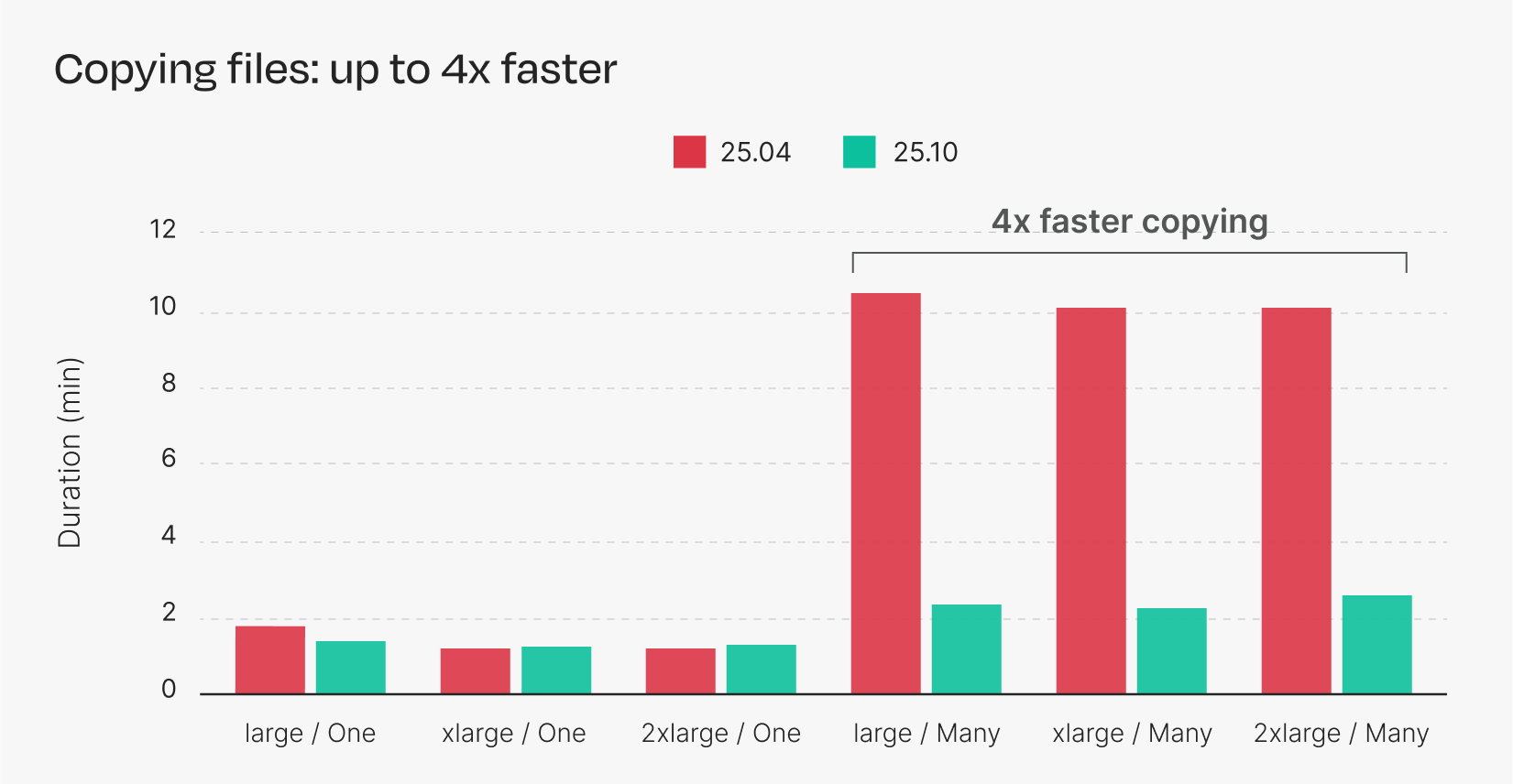
Figure 1. Duration of S3 copies across multiple instance types. Each bar is the average of five repeated runs.
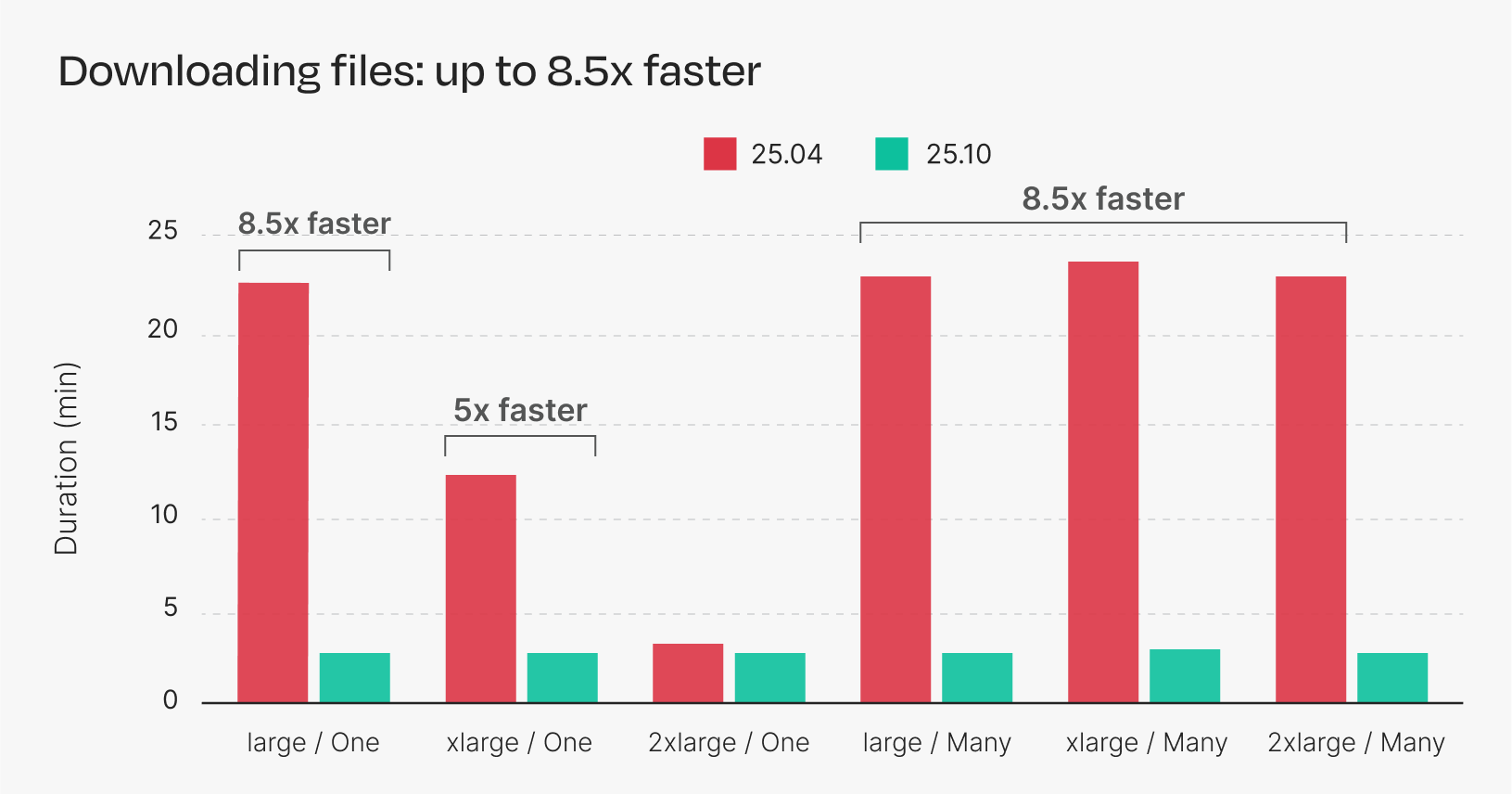
Figure 2. Duration of S3 downloads across multiple instance types. Each bar is the average of five repeated runs.
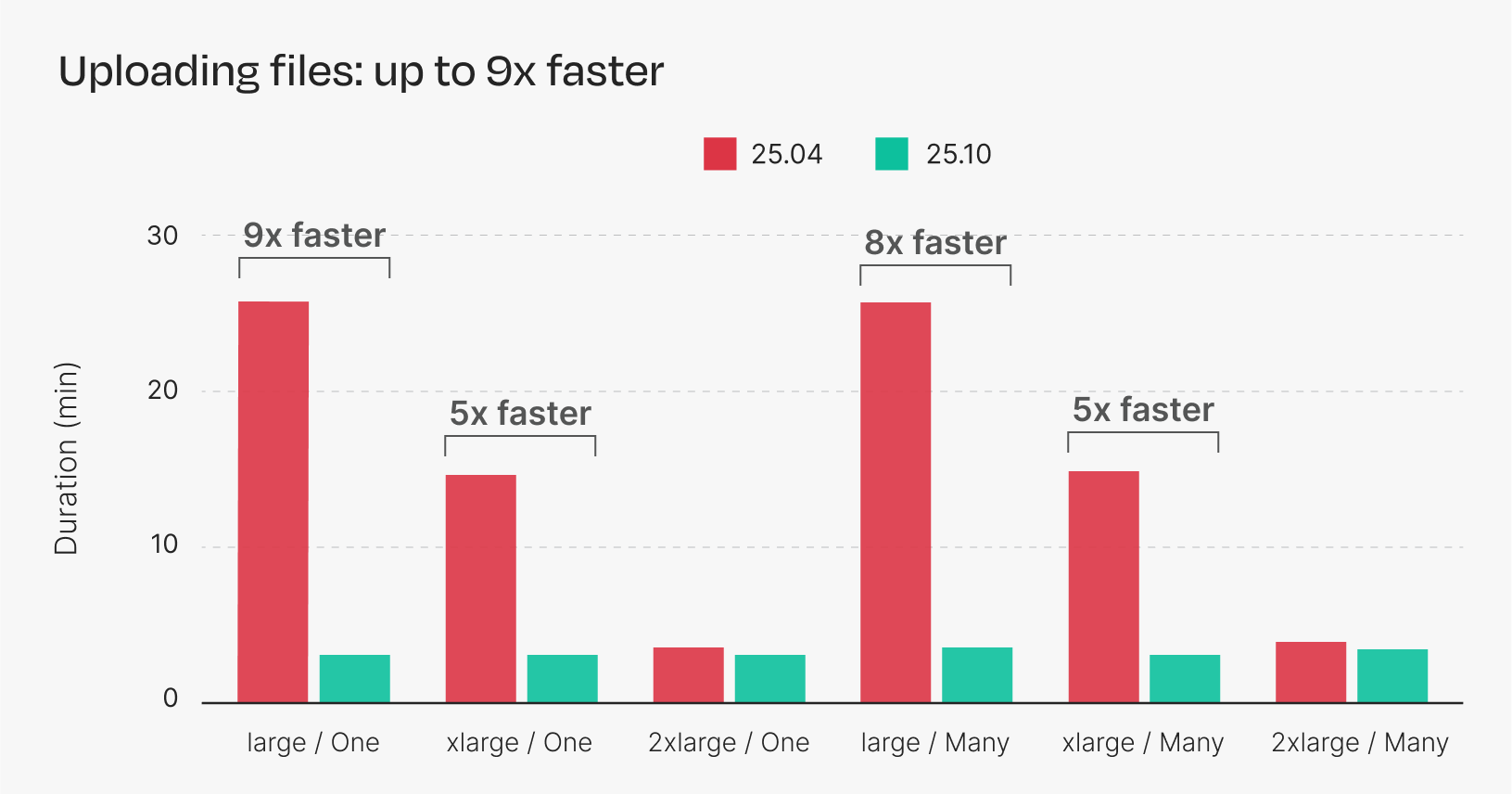
Figure 3. Duration of S3 uploads across multiple instance types. Each bar is the average of five repeated runs.
With Nextflow 25.04, a larger instance is needed to achieve optimal performance for most S3 operations, and in the case of copying and downloading many files, the larger instance doesn’t improve performance at all.
Nextflow 25.10, however, achieves optimal performance across the board, even with smaller instances. The new implementation makes better use of multi-threading and multi-part uploads, allowing it to perform S3 transfers more efficiently and with fewer resources.
Publishing many files
In the second benchmark, we measured the publishing time, or the time spent publishing files during a workflow run. We created a synthetic pipeline that creates files with random content and publishes them to S3. We ran the pipeline on AWS Batch with separate S3 buckets for the work directory and output directory.
You can run the benchmark yourself using this pipeline example:
This pipeline uses the collect operator to force Nextflow to wait for all tasks to complete before publishing any files. Publishing is normally interleaved with task execution, which improves overall performance but makes it difficult to isolate the publishing time, which we need here in order to measure the improvement provided by 25.10.
The results are shown below:
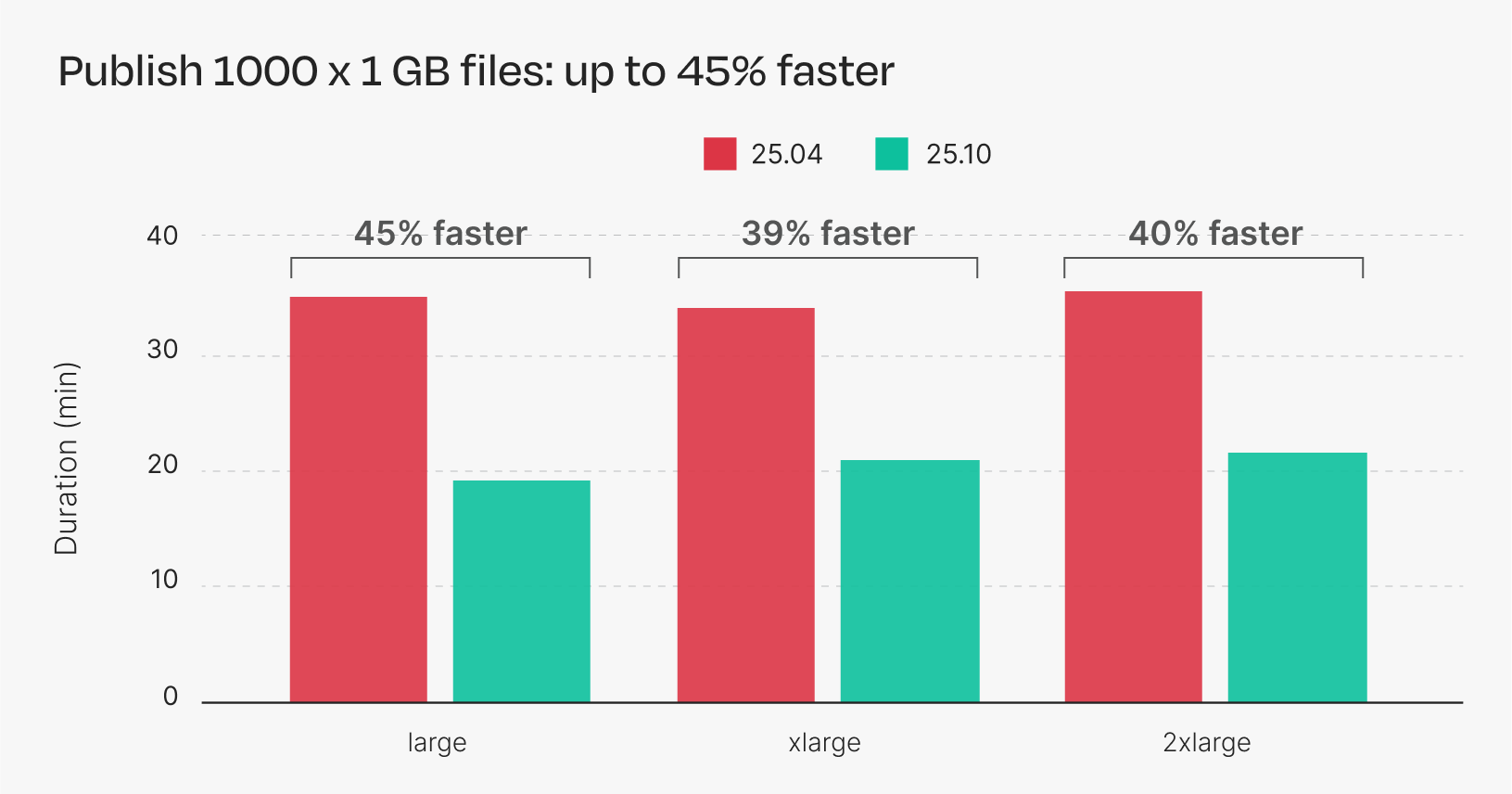
Figure 4. Publishing time of synthetic pipeline. Each bar is the average of five repeated runs.
Nextflow 25.10 provides a 45% reduction in publishing time in this benchmark by performing more S3 copies in parallel. Additionally, there is little difference in runtime across different instance types. This is because Nextflow performs an “S3-to-S3 copy” when publishing a file from one S3 bucket to another, which does not require any local disk I/O and therefore is not bottlenecked by the head node itself.
Conclusion
Nexflow 25.10 uses the AWS SDK v2, which provides better performance for S3 transfers. As we show in the benchmarks, Nextflow 25.10 performs S3 transfers more efficiently than previous versions, and with smaller instances for the head node.
Keep in mind that the actual improvement will depend on the size and shape of your pipeline:
- →Pipelines that spend a significant amount of time publishing files after all tasks have completed will see the most improvement in overall runtime. Pipelines that already interleave most of the output publishing with task execution will not see as much improvement.
- →Pipelines that use S3 for both the work directory and output directory should be less sensitive to the size of the head node, since Nextflow uses S3-to-S3 copies in this case. Pipelines that use a shared filesystem for the work directory may require a larger head node for large runs, but will perform more efficiently than before on smaller instances.
See the 25.10 migration notes for more information, and keep an eye out for future improvements as we continue to optimize the Nextflow and the S3 integration.