
Suppose you've been working on a production pipeline for months. You've carefully crafted containers optimized for each application, thoroughly tested the pipeline with different data sets, had it peer-reviewed, and done everything you can to make it reliable and bulletproof. Now, imagine a colleague comes along and claims that a simple optimization can make your pipeline run ~40% faster and reduce costs by ~6x. You probably wouldn't believe them, but it turns out that these kinds of gains are entirely realistic. Read on and learn about resource optimization in Nextflow Tower – an exciting innovation that can lead to dramatic efficiency gains both on-prem and in the cloud.
Pipeline resource requirements
Most of us who have worked in bioinformatics or large-scale computing for any time have probably heard cluster administrators boast about 90%+ cluster utilization. The whole point of schedulers like Slurm, Grid Engine, or cloud-based analogs is to maximize throughput and resource utilization. Administrators sometimes mistakenly assume things are running efficiently just because all their scheduling slots are occupied and jobs are pending in queues.
A dirty little secret is that resource allocations are often shockingly inefficient. In fact, it's not uncommon to overstate resource requirements by an order of magnitude or more. Suppose we have a cluster of two VMs, each with 16 vCPUs and 32GB of RAM. Let us also suppose that a single-threaded task requires at most 2GB of memory, but we request 20GB. In that case, the scheduler will only run one task per VM when there is the capacity to run 16. The result is that pipelines run slowly, costs mount, and resources are severely underutilized, with cores sitting idle. These glaring inefficiencies are not always obvious. Researchers often have little knowledge of the underlying compute environments and how tasks are dispatched. Cluster administrators see the workloads as they manifest on the clusters but have no reason to question resource requirements decided on by pipeline developers that are experts in their field.
Why resource optimization is hard
Bioinformaticians are smart people, but several factors conspire to make resource optimization challenging. Below are a few reasons why the resource requirements coded into production pipelines are often less than optimal:
- →Pipeline developers are mainly concerned with getting pipelines to work reliably and deliver accurate results. Requesting insufficient resources for any step leads to pipelines that crash or hang. Overestimating resources, by contrast, carries no such penalty.
- →Production pipelines need to accommodate data of all shapes and sizes. The compute and memory requirements for analyzing a human genome differ from those for a virus. When developers stress-test pipelines, they use large datasets, so default resource requirements often reflect these large models.
- →In many environments, pipelines run on shared on-premises clusters. Since these costs are fixed and accounted for, the cost impact of inefficient pipelines is not as visible.
- →Ironically, there is also a downside to underestimating resource requirements. Nextflow allows failed tasks to be automatically re-run. Developers typically code resource allocations dynamically, sometimes doubling memory and CPU after a failed task. For tasks that repeatedly fail due to insufficient resources, organizations pay not only for failed runs, but when the task finally succeeds, resources tend to be over-allocated.
Some developers attempt to code resource requirements by inspecting the sizes of datasets at runtime, but this is hard in practice. The file size is not always a good predictor of resource requirements. As a result, developers lump processes into arbitrary buckets using labels, tagging them as small, medium, or large and making broad resource assumptions for each category.
What is Nextflow Tower resource optimization?
Nextflow Tower resources optimization is a new feature in Nextflow Tower aimed specifically at this problem. When Tower runs a pipeline, it collects extensive runtime detail about actual resource usage. It uses this information to present per-process and aggregate statistics for each pipeline run. With its new resource optimization features, Tower takes this one step further. It analyzes actual resource usage and generates a recommended set of per-process resource recommendations. Nextflow Tower aims to optimize resource use while being conservative enough to ensure that pipelines run reliably.
The example below illustrates how this works in practice. The nf-core viralrecon pipeline is a high-quality pipeline used to perform assembly and intra-host/low-frequency variant calling for viral samples. It supports both Illumina and Nanopore sequencing data and is widely used by many organizations. As viralrecon runs, Tower collects detailed task-level metrics for each containerized task, including CPU, memory consumption, and task duration.
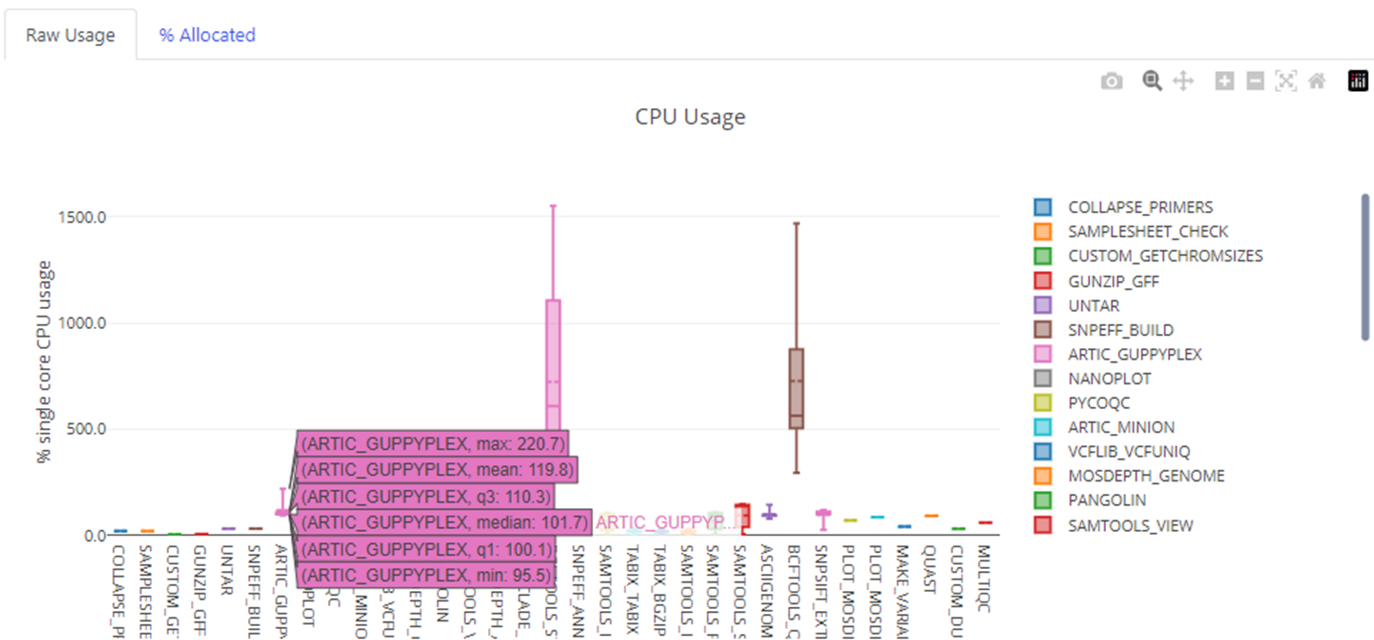
As illustrated above, process steps are called repeatedly with different data sets. Tower captures the full range of resource requirements for each process. Tower then automatically generates optimized per-process resource recommendations that can be entered directly into the pipeline's nextflow.config file.
To illustrate why this is helpful, consider that when viralrecon runs with its default dataset, the pipeline manifests on the underlying compute environment as 1,073 discrete tasks – each requiring widely differing amounts of resources. The ARTIC_GUPPYPLEX process step in the workflow highlighted above is called 49 times with different data and resource requirements with every containerized task. Actual resource use for this process ranges between 0.96 and 2.2 cores across all runs. The viralrecon pipeline allocates 12 cores to this process by default, even though 3 cores would be more appropriate.
Manually inspecting log files for 1,073 tasks to determine CPU and memory usage is a nonstarter – especially when even minor changes to pipelines and datasets can yield different resource requirements every time a pipeline is re-run. If there was ever a case for automation, this is it. The resource optimizer automates this detailed resource analysis so that pipeline users and developers don't have to.
What are the potential savings?
A real example involving the same viralrecon pipeline is provided below. When viralrecon was run without optimization (with the Tower instrumenting resource usage), the pipeline took almost 5 hours and cost approx. USD 9.97 to run using spot instances. After generating and applying optimized resource recommendations, the same pipeline ran in 3 hours at the cost of just USD 1.54 – a 6.5x improvement!1
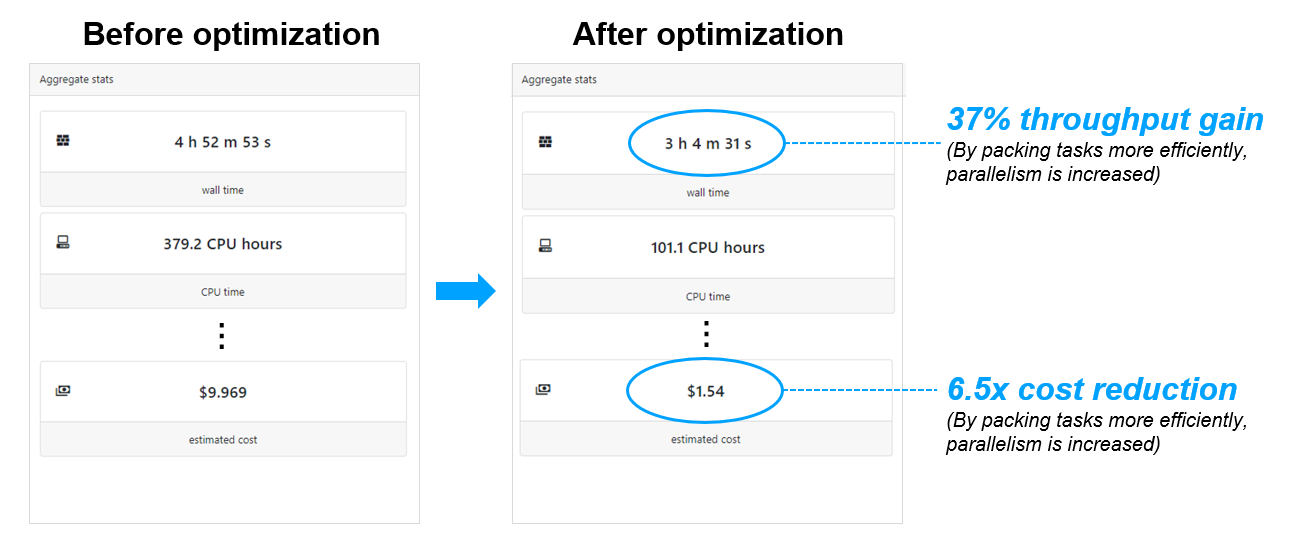
There is no guarantee that every pipeline will see similar efficiency gains, but these results are compelling. Tower's optimization features will be especially helpful for organizations running pipelines developed by others, where default resource requirements may not reflect their typical sample sizes.
Using resource optimization to boost throughput and reduce cost
Resource optimization is not a panacea, of course. Different datasets will always have different resource requirements. However, for organizations performing multiple runs involving similar-sized samples, resource optimization can significantly improve the accuracy of resource estimates resulting in higher utilization and lower cloud spending. Even if the average gain is only 25%, the savings can be enormous for firms spending upwards of $1M per year on cloud resources.
The benefits of resource optimization apply to local compute environments as well. Sites running on-prem HPC environments can support more research using on-prem assets, reduce turnaround times, boost productivity, and avoid tapping expensive cloud resources.
Multi-dimensional gains with Tower
Resource optimization is just one of several ways that Tower can help organizations improve efficiency and reduce costs. Other sources of savings are as follows:
- →Tower automates the provisioning of compute environments using cost-efficient spot instances, potentially increasing their use and reducing overall costs.
- →With built-in support for high-performance cloud storage in Tower, organizations can accelerate pipeline execution, reducing the time for which expensive cloud instances are needed.
- →By attributing a cost to each pipeline, users tend to be more aware of costs and the impact a run will have on resource availability for colleagues. As a result, users are more likely to ensure that a large run is required before launching it.
- →With Tower's intuitive Web UI and collaboration features, sites can reduce erroneous pipeline submissions that result in wasted resources. Also, by making prior runs searchable, Tower helps avoid redundant pipeline execution, reducing cost and improving efficiency.
In Tower, all these gains are cumulative. Even organizations already taking advantage of Tower's cost-saving features can see significant additional gains with resource optimization.
To learn more about Nextflow Tower, visit https://seqera.io/tower
1 Some readers may find it odd that the pipeline runs faster. This is a consequence of Tower and Nextflow being able to pack more tasks onto each underlying VM since the resources requested more accurately reflect resources actually required. This results in a higher degree of parallelism. Performance gains will depend on how much inherent opportunity for parallelism exists in the pipeline.