
Introduction
A Nextflow workflow run consists of the head job (Nextflow itself) and compute tasks (defined in the pipeline script). It is common to request resources for the tasks via process directives such as cpus and memory, but the Nextflow head job also requires compute resources. Most of the time, users don’t need to explicitly define the head job resources, as Nextflow generally does a good job of allocating resources for itself. For very large workloads, however, head job resource sizing becomes much more important.
In this article, we will help you understand how the Nextflow head job works and show you how to tune head job resources such as CPUs and memory for your use case.
Head job resources
CPUs
Nextflow uses a thread pool to run native Groovy code (e.g. channel operators, exec processes), submit tasks to executors, and publish output files. The number of threads is based on the number of available CPUs, so if you want to provide more compute power to the head job, simply allocate more CPUs and Nextflow will use them. In the Seqera Platform, you can use Head Job CPUs or Head Job submit options (depending on the compute environment) to allocate more CPUs.
Memory
Nextflow runs on the Java Virtual Machine (JVM), so it allocates memory based on the standard JVM options, specifically the initial and maximum heap size. You can view the default JVM options for your environment by running this command:
For example, here are the JVM options for an environment with 8 GB of RAM and OpenJDK Temurin 17.0.6:
These settings (displayed in bytes) show an initial and maximum heap size of ~128 MB and ~2 GB, or 1/64 (1.5625%) and 1/4 (25%) of physical memory. These percentages are the typical default settings, although different environments may have different defaults. In the Seqera Platform, the default settings are 40% and 75%, respectively.
You can set these options for Nextflow at runtime, for example:
If you need to provide more memory to Nextflow, you can (1) allocate more memory to the head job and/or (2) use NXF_JVM_ARGS to increase the percentage of available memory that Nextflow can use. In the Seqera Platform, you can use Head Job memory or Head Job submit options (depending on the compute environment) to allocate more memory.
Disk
The Nextflow head job is generally responsible for downloading software dependencies and transferring inputs and outputs, but the details vary depending on the environment:
- →In an HPC environment, the home directory is typically used to store pipeline code and container images, while the work directory is typically stored in high-performance shared storage. Within the work directory, task inputs are staged from previous tasks via symlinks. Remote inputs (e.g. from HTTP or S3) are first staged into the work directory and then symlinked into the task directory.In a cloud environment like AWS Batch, each task is responsible for pulling its own container image, downloading input files from the work directory (e.g. in S3), and uploading outputs. The head job’s local storage is only used to download the pipeline code.
Overall, the head job uses very little local storage, since most data is saved to shared storage (HPC) or object storage (cloud) rather than the head job itself. However, there are a few specific cases to keep in mind, which we will cover in the following section.
Common failure modes
Not enough CPUs for local tasks
If your workflow has any tasks that use the local executor, make sure the Nextflow head job has enough CPUs to execute these tasks. For example, if a local task requires 4 CPUs, the Nextflow head job should have at least 5 CPUs (the local executor reserves 1 CPU for Nextflow by default).
Not enough memory for native pipeline code
Nextflow pipelines are a combination of native Groovy code (channels, operators, exec processes) and embedded shell scripts (script processes). Native code is executed directly by the Nextflow head job, while tasks with shell scripts are delegated to executors. Typically, tasks are used to perform the “actual” computations, while channels and operators are used to pass data between tasks.
However much Groovy code you write, keep in mind that the Nextflow head job needs to have enough memory to execute it at the desired scale. The simplest way to determine how much memory Nextflow needs is to iteratively allocate more memory to the head job until it succeeds (e.g. start with 1 GB, then 2 GB, then 4 GB, and so on). In general, 2-4 GB is more than enough memory for the Nextflow head job.
Not enough memory to stage and publish files
In Nextflow, input files can come from a variety of sources: local files, an HTTP or FTP server, an S3 bucket, etc. When an input file is not local, Nextflow automatically stages the file into the work directory. Similarly, when a publishDir directive points to a remote path, Nextflow automatically “publishes” the output files using the correct protocol. These transfers are usually performed in-memory.
Many users have encountered head job errors when running large-scale workloads, where the head job runs out of memory while staging or publishing files. While you can try to give more and more memory to Nextflow as in the previous example, you might be able to fix your problem by simply updating your Nextflow version. There have been many improvements to Nextflow over the past few years around file staging, particularly with S3, and overall we have seen fewer out-of-memory errors of this kind.
Not enough disk storage to build Singularity images
Singularity / Apptainer can download and convert Docker images on the fly, and it uses the head job’s local scratch storage to do so. This is a common pattern in HPC environments, since container images are usually published as Docker images but HPC environments usually require the use of a rootless container runtime like Singularity. In this case, make sure the head job has enough scratch storage to build each image, even if the image is eventually saved to shared storage.
Since Nextflow version 23.10.0, you can use Wave to build Singularity images for you. Refer to the Nextflow documentation for more details.
Additionally, Nextflow version 23.11.0-edge introduced support for Singularity OCI mode, which allows Singularity / Apptainer to use the OCI container format (the same as Docker) instead of having to build and store a SIF container image locally.
Failures due to head job and tasks sharing local storage
There are some situations where the head job and tasks may run on the same node and thereby share the node’s local storage, for example, Kubernetes. If this storage becomes full, any one of the jobs might fail first, including the head job. You can avoid this problem by segregating the head job to its own node, or explicitly requesting disk storage for each task so that they each have sufficient storage.
Virtual threads
Virtual threads were introduced in Java 19 and finalized in Java 21. Whereas threads in Java are normally “platform” threads managed by the operating system, “virtual” threads are user-space threads that share a pool of platform threads. Virtual threads use less memory and can be context-switched faster than platform threads, so an application that uses a fixed-size pool of platform threads (e.g. one thread per CPU) could instead have thousands of virtual threads (one thread per “task”) with the same memory footprint and more flexibility – if a virtual thread is blocked (i.e. waiting on I/O), the underlying platform thread can be switched to another virtual thread that isn’t blocked.
Since Nextflow 23.05.0-edge, you can enable virtual threads by using Java 19 or later and setting the NXF_ENABLE_VIRTUAL_THREADS environment variable to true. Since version 23.10.0, when using Java 21, virtual threads are enabled by default.
Initial Benchmark: S3 Upload
Virtual threads are particularly useful when there are many I/O-bound tasks, such as uploading many files to S3. So to demonstrate this benefit, we wrote a pipeline… that uploads many files to S3! Here is the core pipeline code:
The full source code is available on GitHub.
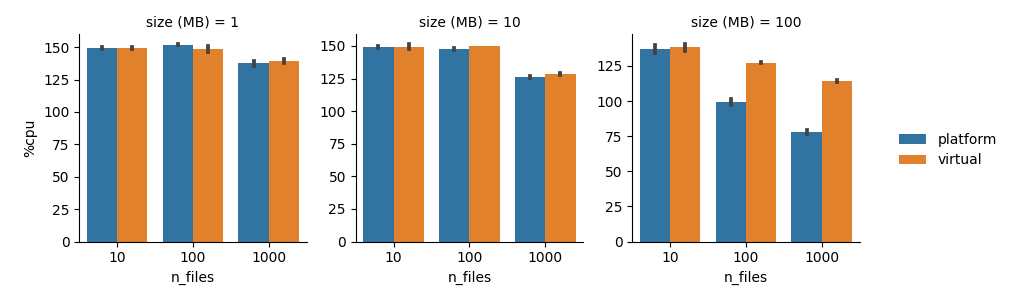
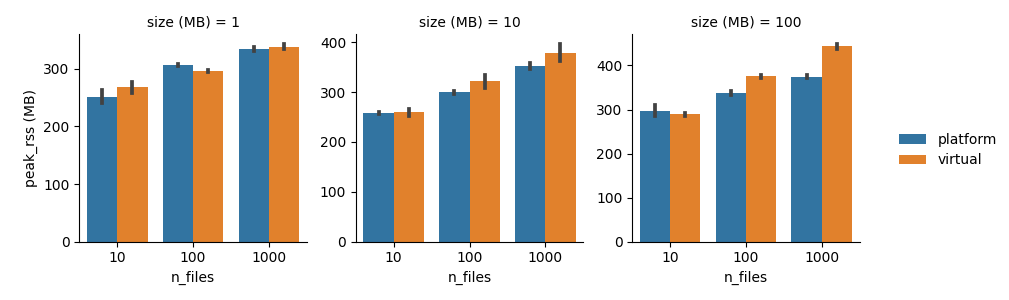
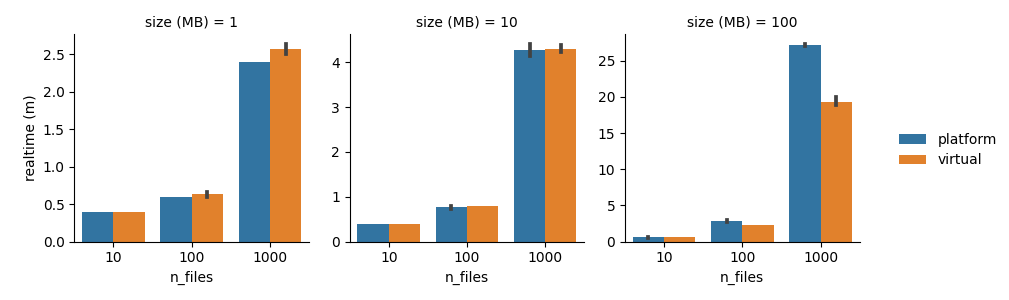
We ran this pipeline across a variety of file sizes and counts, and the results are shown below. Error bars denote +/- 1 standard deviation across three independent trials.
At larger scales, virtual threads significantly reduce the total runtime, at the cost of higher CPU and memory usage. Considering that the head job resources are typically underutilized anyway, we think the lower time-to-solution is a decent trade!
The reason why virtual threads are faster in this case is that Nextflow usually spends extra time waiting for files to be published after all tasks have completed. Normally, these publishing tasks are executed by a fixed-size thread pool based on the number of CPUs, but with virtual threads there is no such limit, so Nextflow can fully utilize the available network bandwidth. In the largest case (1000x 100 MB files), virtual threads reduce the runtime by over 30%.
Realistic Benchmark: nf-core/rnaseq
To evaluate virtual threads on a real pipeline, we also ran nf-core/rnaseq with the test profile. To simulate a run with many samples, we upsampled the test dataset to 1000 samples. The results are summarized below:
| Walltime | Memory | |
|---|---|---|
| Platform threads | 2h 51m | 1.5 GB |
| Virtual threads | 2h 47m | 1.9 GB |
As you can see, the benefit here is not so clear. Whereas the upload benchmark was almost entirely I/O, a typical Nextflow pipeline spends most of its time scheduling compute tasks and waiting for them to finish. These tasks are generally not I/O bound and do not block for very long, so there may be little opportunity for improvement from virtual threads.
That being said, this benchmark consisted of only two runs of nf-core/rnaseq. We didn’t perform more runs here because they were so large, so your results may vary. In particular, if your Nextflow runs spend a lot of time publishing outputs after all the compute tasks have completed, you will likely benefit the most from using virtual threads. In any case, virtual threads should perform at least as well as platform threads, albeit with higher memory usage in some cases.
Summary
The key to right-sizing the Nextflow head job is to understand which parts of a Nextflow pipeline are executed directly by Nextflow, and which parts are delegated to compute tasks. This knowledge will help prevent head job failures at scale.
Here are the main takeaways:
- →Nextflow uses a thread pool based on the number of available CPUs.
- →Nextflow uses a maximum heap size based on the standard JVM options, which is typically 25% of physical memory (75% in the Seqera Platform).
- →You can use
NXF_JVM_ARGSto make more system memory available to Nextflow. - →The easiest way to figure out how much memory Nextflow needs is to iteratively double the memory allocation until the workflow succeeds (but usually 2-4 GB is enough).
- →You can enable virtual threads in Nextflow, which may reduce overall runtime for some pipelines.