
One of the reasons for Nextflow's popularity is that it decouples pipeline logic from underlying execution environments. This, in combination with support for multiple data protocols, source code management systems, container runtimes, and registries, allows users to quickly write pipelines that are portable across compute environments – from notebooks to large on-prem clusters to various cloud services.
In the recent State of the Workflow 2022 Community Survey, 36% of Nextflow users shared that they presently run pipelines in the cloud, and 68% have plans to migrate to the cloud. AWS Batch is consistently one of the most popular execution environments among Nextflow users. While Nextflow's integration with AWS Batch makes running in the cloud easy, as with any "black box" a lot is happening inside the integration. It is helpful to understand the integration in detail to use cloud resources more efficiently and troubleshoot potential problems.
In this series of articles, we look closely at how to use Nextflow with AWS Batch, explain how the integration works, and discuss different deployment options.
In this first article, we will cover the following topics:
- →About AWS Batch
- →AWS Batch Concepts
- →The Nextflow Execution Model
- →The Nextflow – AWS Batch Integration
- →The User Experience
- →Configuring AWS Batch for Use with Nextflow
- →Running a Pipeline on AWS Batch
- →What's Going on Under the Covers?
- →Summary
About AWS Batch
As the name implies, AWS Batch is a fully managed service designed to efficiently run large numbers of batch computing jobs at scale on AWS.
Unlike traditional HPC clusters, where administrators need to manage on-prem or cloud-based resources explicitly, provisioning in AWS Batch is automatic. AWS Batch aims to provide the optimal quantity and type of cloud-based compute instances depending on workload and keeps them active for only as long as they are needed. Some advantages of AWS Batch are:
- →Organizations can avoid the need for costly on-premises infrastructure.
- →No need to install and manage traditional workload managers such as Slurm or SGE.
- →Access to a wide varitety of architectures (FPGAs/GPUs/ARM).
- →Users can scale capacity based on changing demandScale to zero.
AWS Batch Concepts
The batch service works by accepting jobs into job queues and then dispatching those jobs to one or more pre-configured AWS compute environments. Before jobs can be submitted to AWS Batch, Nextflow administrators need to create one or more compute environments in AWS Batch and associate them with job queue(s). Some key elements of AWS Batch are:
Jobs
Jobs refer to the unit of work started under the control of AWS Batch. In a Nextflow context, jobs correspond to individual process steps in a Nextflow pipeline. An important thing to realize about AWS Batch is that jobs actually execute using Amazon Elastic Container Service (ECS) so all jobs run in containers. Containerized jobs typically reference a container image, a command to execute in the container, and any parameters associated with the job. For Nextflow users, creating and submitting jobs is handled automatically by the Nextflow Batch integration.
Job Queues
Before a Nextflow task can be submitted to AWS Batch, at least one job queue must be created. Each queue can have an associated priority (an integer between 0 and 1000) and each queue needs to be associated with at least one compute environment. The compute environments associated with each queue must be of the same type (e.g EC2 on-demand or EC2 spot). Job queues will attempt to dispatch jobs to compute environments based on the order in which they are listed in the queue definition.
Compute Environments
Compute environments in AWS Batch can be managed or unmanaged. With Nextflow, managed compute environments are typically used, where AWS Batch scales compute resources automatically based on resource demand. Administrators need to define compute environment themselves and provide details such as:
- →The provisioning model to be used for compute resources – e.g. ec2 on-demand, ec2 spot, fargate, or fargate spot instances.
- →The minimum and maximum number of vCPUs per compute environment.
- →The EC2 instance types that can be used to support the environment.
- →The percentage of on-demand prices that you are willing to pay for Spot instances.
- →Additional details such as resource allocation strategies and whether custom Amazon Machine Images (AMIs) are to be used.
Job Definitions
Before any job can be submitted to AWS Batch, a job definition needs to be created describing each type of job. Job definitions provide details about how jobs should be handled in AWS Batch including the job type (single node or parallel), execution timeouts, the container image in which the job will execute, and more. Fortunately, the Nextflow AWS Batch integration transparently creates job definitions on the fly, so Nextflow users don't need to worry about creating job definitions. Understanding job definitions is helpful however when monitoring pipeline execution or troubleshooting jobs in AWS.
For users familiar with traditional batch queuing systems such as Slurm, PBS, LSF, or Grid Engine, AWS Batch can seem a little awkward and unfamiliar. There is no simple qsub or bsub command that makes it easy to launch a script or binary from the command line. Once you get used to the execution model, however, the batch service turns out to be a convenient way to execute pipelines in the cloud.
While it is possible to submit AWS Batch jobs via AWS CLI or the AWS Console, in practice, AWS Batch jobs tend to be submitted programmatically. AWS Batch exposes a RESTful API where rich JSON directives can be posted to various endpoints, Users can also submit jobs to AWS Batch using various language-specific SDKs. This latter approach is used with Nextflow.
The Nextflow Execution Model
Before delving into details of the AWS Batch integration, a quick review of Nextflow's execution model and executors may be helpful to some readers. In Nextflow, pipelines are comprised of a logically connected set of processes, each with a defined set of inputs and outputs. While the overall pipeline logic is implemented using a domain-specific language (DSL), the logic associated with each process step can be implemented in any scripting language that can execute on a Linux platform (Bash, Perl, Ruby, Python, etc)
Rather than running in a prescribed sequence, process steps execute when their input channels become valid. For this reason, Nextflow is said to be "reactive". Process execution occurs as a reaction to a change in a process step's inputs.
An example from the Nextflow documentation is provided below. A process called extractTopHits is executed when the input parameter (top_hits) becomes valid. In Nextflow, the logic encapsulated by the three double quotes (“"”) runs by default in a local shell on the machine where the pipeline is executing.
This syntax makes coding Nextflow process logic straightforward. Nextflow makes no assumptions about where a process step will execute. For example, the process might execute locally (finding the blastdbcmd in a local /bin directory), it may run in a container pulled from a registry, or it may run on a compute node attached to an HPC cluster on-premises or in a public or private cloud.
Nextflow abstracts away this runtime complexity by using Executors. Executors are a component in the Nextflow architecture that determines where a pipeline process is run and supervises its execution. Executors look after details such as moving commands and input files to the target environment, and submitting jobs and monitoring the execution using the appropriate APIs corresponding to the target compute platform.
By storing details about the execution environment in a separate nextflow.config file, pipelines can be made portable, allowing them to execute anywhere with no change in pipeline syntax. AWS Batch is just one of roughly a dozen execution platforms supported by Nextflow.
The Nextflow AWS Batch Integration
Support for AWS Batch was introduced in 2017, in Nextflow 0.26.0, less than a year after AWS Batch was announced. The Nextflow – AWS Batch integration enables Nextflow pipelines to scale transparently on the AWS cloud. Prior to the availability of AWS Batch, most Nextflow users running pipelines in AWS needed to provision and manage their own EC2 instances.
As explained earlier, AWS Batch jobs are always executed in a container. Individual process steps (tasks) can re-use the same container, or optionally use different container images for different process steps. Some features of the integration are as follows:
- →Transparent support for containerized Nextflow pipelines.
- →Automatic scaling of cloud resources (via AWS Batch managed compute environments).
- →The ability to automatically retry failed tasks.
- →The ability to select different queues and AWS regions from within Nextflow.
- →Built-in support for AWS Identity and Access Management (IAM) credentials.
- →Access to on-demand and Spot instances (depending on compute environment definitions).
- →Support for Amazon S3 as a mechanism to stage data and executables, store intermediate files, and make data available transparently to AWS Batch jobs.
How the Integration Works
At a high level, the integration with open source Nextflow works as shown in the diagram below. Nextflow users run pipelines as they normally would but reference a Nextflow configuration file (nextflow.config) that instructs Nextflow to use the AWS Batch executor. The configuration file provides other detail needed for the integration such as the queue name, AWS Region, and path to the AWS CLI command. The CPU and memory requirements associated with individual workflow steps can be encoded in the Nextflow workflow
We can launch a proof-of-concept RNA sequencing workflow residing in a Nextflow GitHub repository by executing the command below:
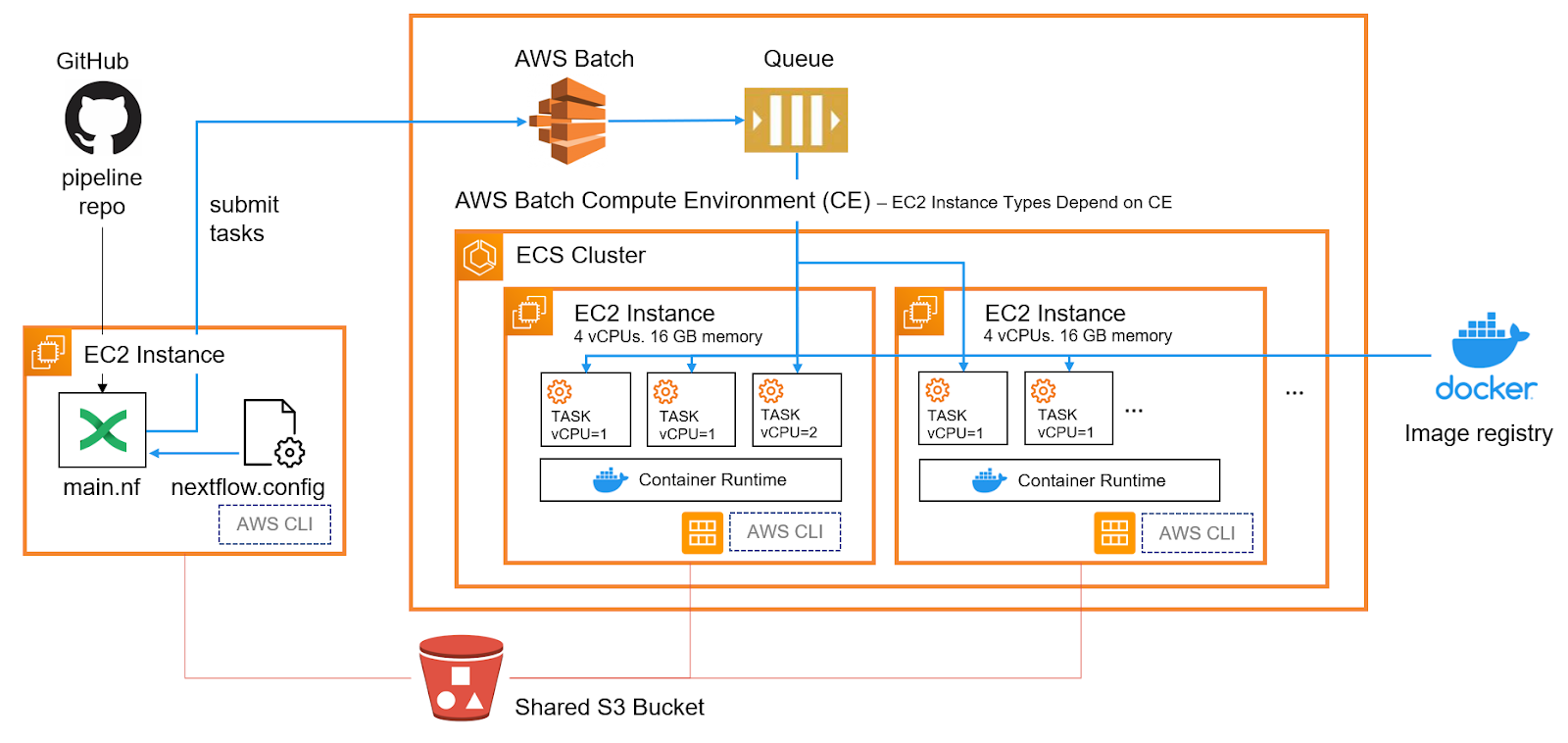
The Nextflow command provides the path to the nextflow.config. Optionally, the .nextflow.config file in the user's home directory can also be customized. A Nextflow configuration file that will use AWS Batch to execute pipelines is provided below:
Sample nextflow.config file for AWS Batch
Workflows can be submitted from any client where Nextflow is installed including a desktop or laptop computer. In our example, we've chosen to run Nextflow from a cloud EC2 instance rather than a client device. The advantage of submitting pipelines from a cloud instance is that we don't need to maintain a persistent network connection to the AWS Batch service from our client computer. Users can launch a long-running pipeline, power down their laptop, and the pipeline continues to execute.
Individual AWS Batch Jobs are launched as containerized jobs on the ECS cluster used by AWS Batch. AWS Batch job will attempt to use CPU and resources efficiently, typically starting mutltiple containers per cluster host depending on task resource requirements and the size of the underlying EC2 instances.
In a managed AWS Batch environment (recommended), if sufficient EC2 instances are not already running to support the workload, new instances are started automatically and added to the ECS cluster. The EC2 instance type is determined by the definition of the compute environment in AWS Batch. Suppose the instance type is set to “optimal” (the default). In that case, AWS Batch will attempt to start the most appropriate instance types depending on the resource requirements of the workload.
How Nextflow Simplifies the Use of AWS Batch
It's worth mentioning that the Nextflow integration automates many steps that would otherwise be manual and tedious to configure and manage in AWS Batch. For example, before running a job in AWS Batch, users are required to create job definitions as explained in the AWS Batch Documentation. (See Creating a single-node job definition). The job definition includes scheduling parameters, execution roles, details about the container image where the job will execute, and the resources required to execute the container. Complicating things further, pipelines are normally comprised of multiple steps. A separate job definition is required for each unique combination of container and set of resource requirements.
Similarly, users would need to worry about handling data for each process step. This would involve moving input data from shared storage, ensuring that it is accessible in the container, and storing data in a location where the next process step can retrieve it.
Pipelines frequently have dozens of steps. Performing these activities for every pipeline is too complex and error-prone to be practical. The Nextflow integration allows users to sidestep all this complexity when dealing with AWS Batch.
The User Experience
From the perspective of a Nextflow user, pipelines run as they always do. The Nextflow AWS Batch integration handles all the details including staging data in S3, creating AWS Batch job definitions, ensuring that any Docker images needed for containerized execution are available on ECS cluster nodes, and retrieving results from AWS Batch as inputs to the next step in a Nextflow pipeline.
Below is an example of running a pipeline from the command line:
The start-up time for tasks under AWS Batch may be a little longer than for a dedicated on-premises cluster. If instances underpinning the AWS ECS cluster are not already started (because we've set the minimum number of vCPUs in the compute environment to zero), EC2 nodes will need to be provisioned and added to ECS before AWS Batch can dispatch jobs.
Users with access to the AWS Console (or AWS CLI) can monitor the execution of the Nextflow pipeline in AWS Batch. In the nextflow.config file, we indicated jobs were to be submitted to the aws-batch-nextflow queue. Within the AWS Batch interface, we can monitor jobs submitted to that queue and monitor execution as shown:
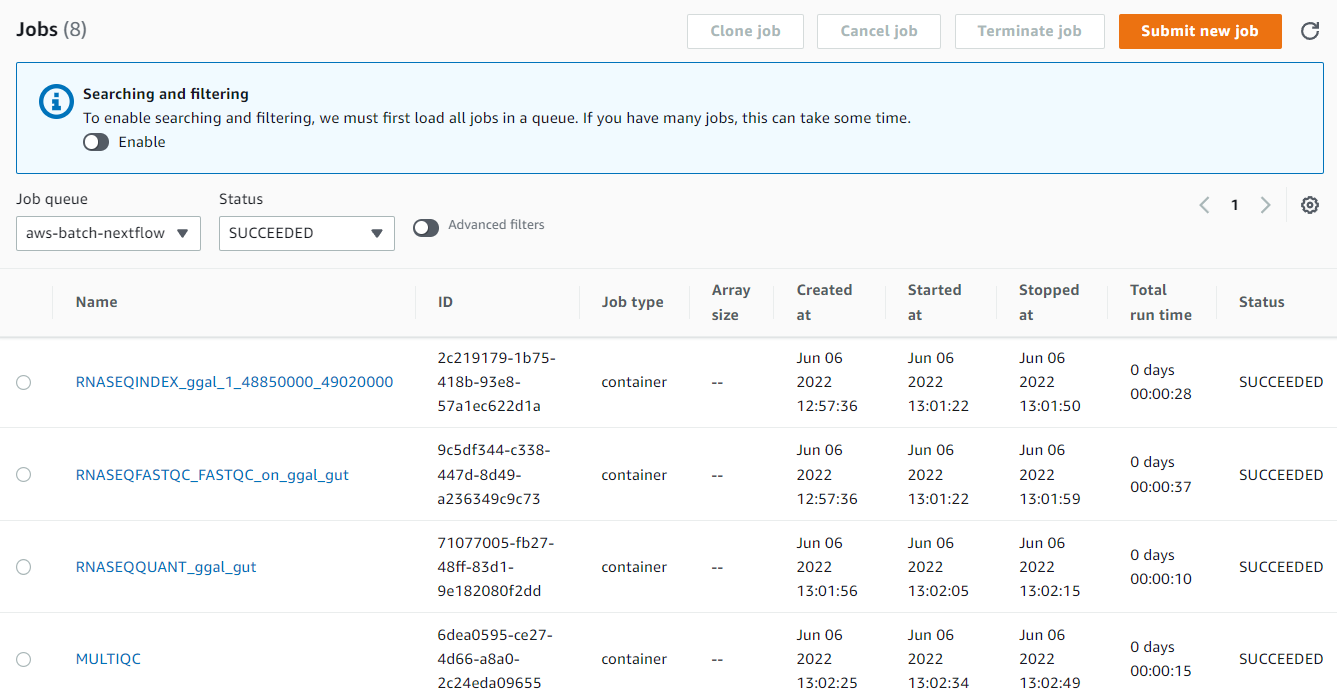
Clicking on any of the job names in the interface above provides us with details about the execution of each process step in the workflow. We can see details about every job that ran including the actual command run within the container.
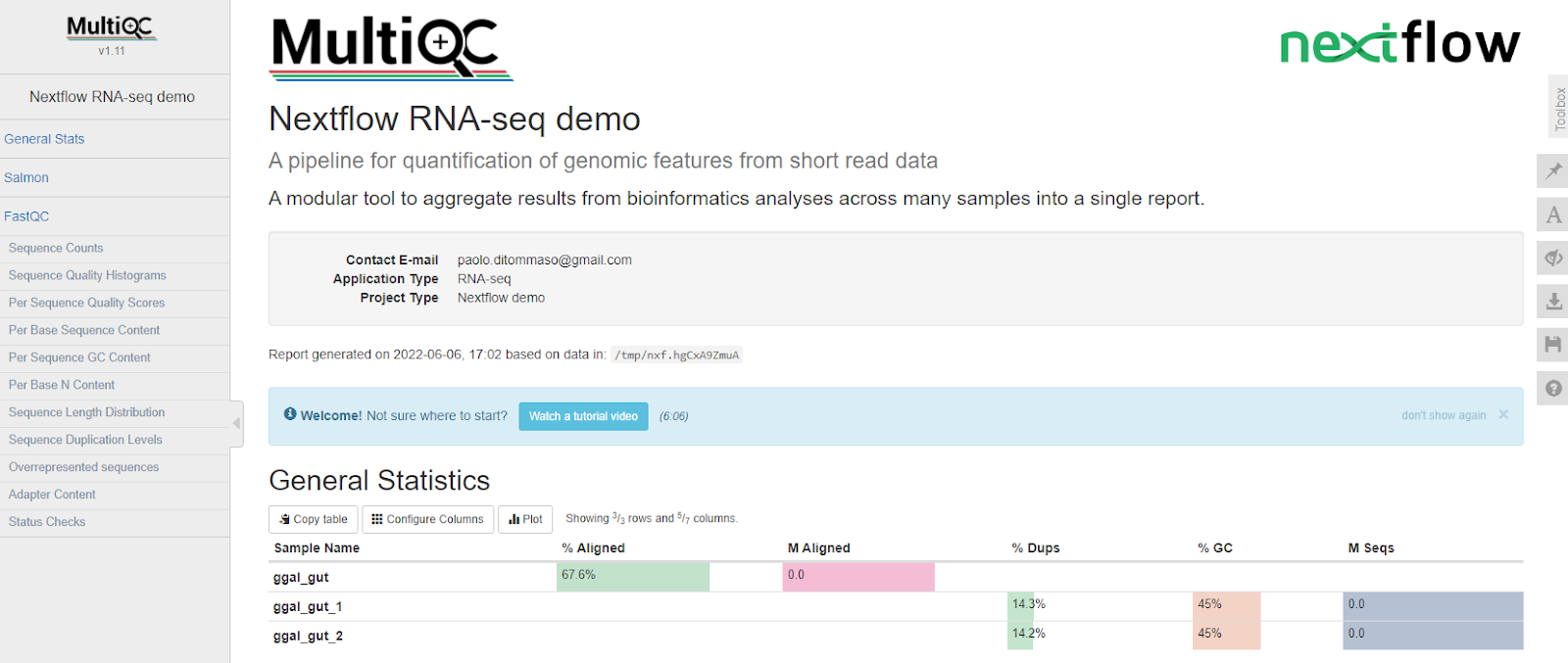
Examining the multiqc_report.html file placed in the ~/results directory after pipeline execution shows that our pipeline ran successfully under AWS Batch.
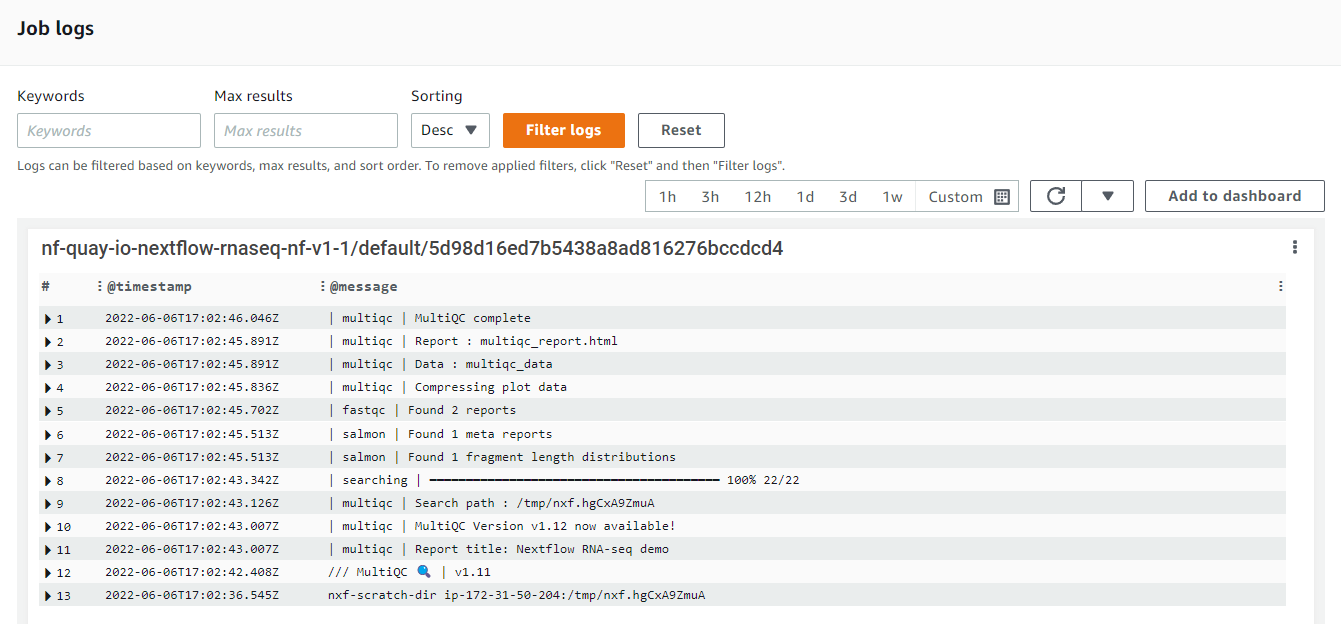
It's worth mentioning that AWS Batch is closely integrated with Amazon CloudWatch. If you accept the incremental charges associated with the use of CloudWatch, detailed logs of pipeline execution will be available through CloudWatch as shown below. This can help administrators troubleshoot problems and optimize pipelines for reliability, performance, and cost-efficiency.
In follow-on articles we will:
- →Provide a step-by-step guide to deploying AWS Batch with Nextlow and explore details of the integration
- →Explore an even easier integration method using Nextflow Tower
For more information about the AWS Batch Integration with Nextflow and Tower, reach out to us and book a demo.