
In Part 1 of our Modernizing the Nextflow Developer Experience blog series, we introduced the new and improved Nextflow Visual Studio Code (VS Code) extension. The extension streamlines the Nextflow development process, making it easier than ever before to read, write, and debug scripts.
The Nextflow VS Code extension is available to download from the VS Code marketplace. If you missed our presentation about the extension at the Nextflow Summit Barcelona, you can catch the recording here.
The community response to the extension has been incredible. Developers have shared their enthusiasm and how it has improved their developer experience. We hope to see many more posts like these as we continue to improve the extension and add features.
“This preview DAG feature from the language server just enhanced my nextflow developer experience 10x 🎉 Thank you! YOU ARE AWESOME”
—Sateesh Peri, Perimatrix IT Consultancy
“Thanks a lot for all the explanations. This plugin will be really useful for the whole community!”
—Louis LeNezet, University of Rennes
In Part 2, we’ll explore the technical backbone of the new VS Code extension—the language server. We will unpack how it works, how it’s revolutionizing the way we write Nextflow, and what’s on the horizon.
The language server
The updated Nextflow VS Code extension's driving workhorse is the Nextflow language server. To understand why the language server is important, we first need to understand how Nextflow executes a script, handles errors, and fits within the typical development cycle.
Previously, to detect problems in our code, we had to run it with the Nextflow CLI. In a very simplified way, the nextflow run command can be boiled down into three steps:
- Read, parse, and analyze the code
- If any errors are detected, print them to the console and exit
- If no errors are detected, execute the compiled code
Consequently, the typical development cycle looks something like this:
- Write some Nextflow code
- Execute
nextflow run - It failed! Check the log!
- Find the offending code
- Fix the offending code
- Go back to step 2 and try again
This is essentially how software has always been developed, and though the syntax and tooling may differ, this process remains remarkably similar from one programming language to another.
So what’s the big deal about the Nextflow language server? Put simply, the Nextflow language server can understand Nextflow code without running the code. Accordingly, the way it handles errors is somewhat different:
- Load and parse all Nextflow scripts in the workspace
- Report any errors in the editor
- Whenever edits are made, re-analyze the script and update the errors in the editor
With the Nextflow language server, the development cycle now looks like this:
- Write some Nextflow code
- Fix any errors as they appear in the editor
- Execute the code with
nextflow run
The Nextflow language server can be thought of as an interactive version of the Nextflow CLI. While it can’t execute our code, it can continuously analyze it. Importantly, it shows the errors exactly where they appear, rather than making users run and look for the offending code. This early feedback is essential for fast iteration and allows users to go from an idea to a result quicker than ever before.
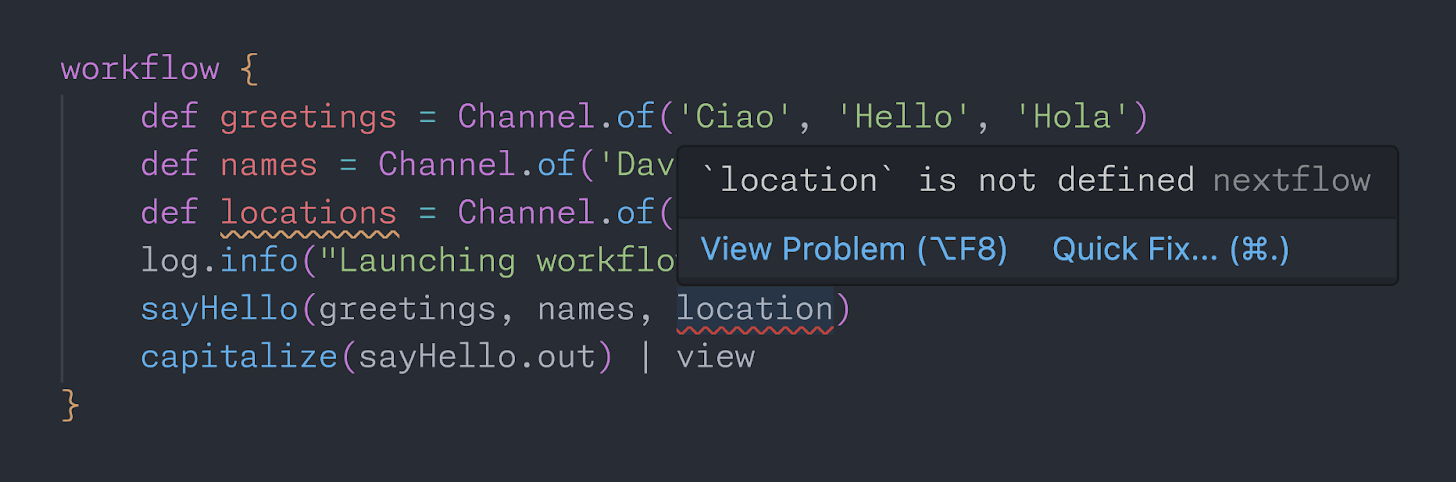
Error reported by the VS Code extension.
Language server protocol
Inline error reporting is nothing new. Integrated development environments (IDEs) have offered this functionality for decades. The key innovation of the language server is the Language Server Protocol (LSP), a protocol developed by Microsoft to decouple language-specific features (like inline error reporting) from specific IDEs. This way, instead of every IDE reimplementing the same features for a given language, the language server can be developed once and then used by multiple IDEs. In other words, each IDE becomes a client of the same language server.
Take the Nextflow VS Code extension as an example. The extension code implements commands to start and stop the language server, as well as some editor-specific logic for rendering Mermaid diagrams. That’s it! All of the actual language features, such as error checking, hover hints, and code completion, are implemented in the language server.
Supporting additional editors is simply a matter of writing a small plugin to start the language server and connect it to the editor. In fact, this effort is already underway for popular editors. An extension for other preferred editors may be available by the time this blog is published. A special thanks to Edmund Miller for leading a large part of this effort.
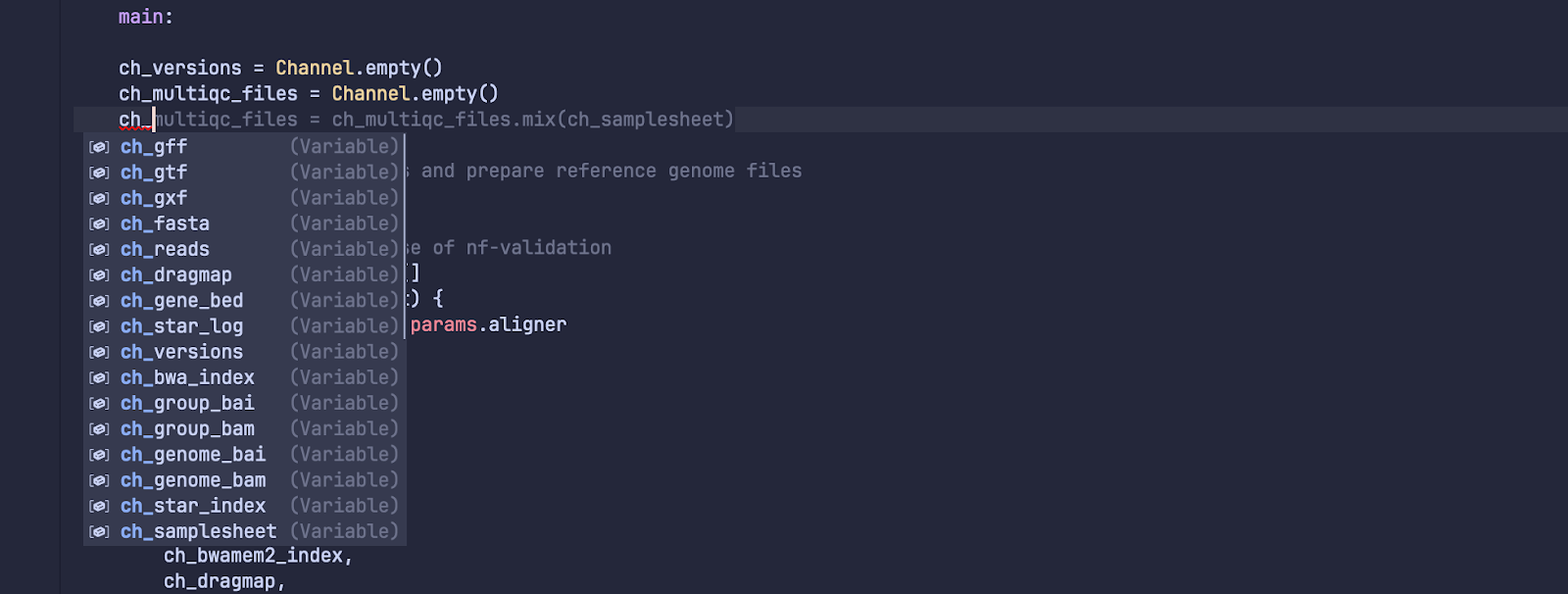
Code completions in Emacs.
As the Nextflow language server is a Java application it can run anywhere Nextflow can. The language server runs as another background process that the editor manages. It can run on your laptop, Gitpod, Data Studios, or anywhere else VS Code is run.
Mechanics
So how is the language server able to provide all of the features we showcased in Part 1? And why is it able to report so many different kinds of errors?
In the spirit of Nextflow pipelines, we have visualized Nextflow’s compilation pipeline as a Mermaid diagram! Here you can see all of the steps involved in translating Nextflow code to a directed acyclic graph (DAG) that Nextflow can execute. The left-hand path, starting with “parse V1”, shows how it currently works in the Nextflow CLI, while the right-hand path starting with “parse V2” shows how it works with the language server.
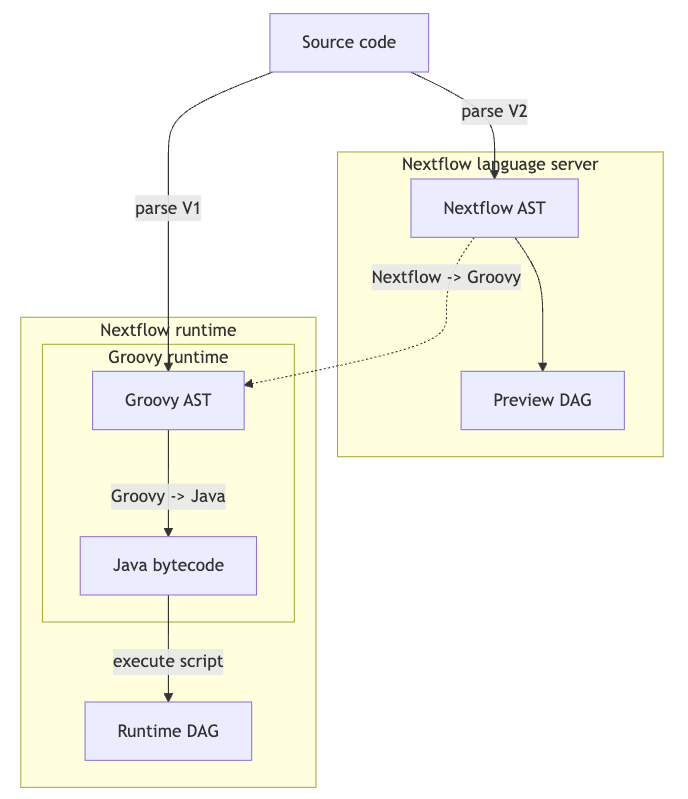
Nextflow’s compilation pipeline.
Building the AST
The first step in any compiler is to translate source code (which is just text) into a data structure that can be analyzed and manipulated. Virtually every programming language, including Nextflow, can be represented as a tree, also known as an abstract syntax tree (AST). Both the Nextflow CLI and language server translate Nextflow source code into a Groovy AST, but how they get there is quite different.
The Nextflow CLI delegates nearly all of the script compilation to the Groovy runtime, with a small amount of extra logic to handle things like process and workflow definitions. This approach has a few notable implications:
- →Nextflow scripts are essentially Groovy scripts with some extra sugar for processes, workflows, and includes. Any Groovy syntax can be used in a Nextflow script.
- →Nextflow concepts like processes and workflows are not first-class citizens in the AST. Instead, they are described in terms of underlying Groovy concepts. For example, a process definition is just a function call in the Groovy AST, and the process “body” is just a closure.
- →An invalid Nextflow script might still be a valid Groovy script. If the user makes a mistake in their code, it might not get caught by the Groovy compiler. Depending on the kind of mistake, it might get caught by Nextflow’s custom AST logic, while the pipeline is running, or not at all. Even if the mistake is caught early, the corresponding error message might seem unrelated because the Groovy compiler doesn’t know anything about the Nextflow language.
On the other hand, the language server completely bypasses the Groovy parser and uses a custom parser specifically for Nextflow scripts and config files. This parser, while based on the Groovy parser, only understands the syntax that is considered part of “the Nextflow language.” This approach has a different set of implications:
- →Nextflow scripts only allow a subset of Groovy syntax and, in theory, could allow syntax that is not valid in Groovy.
- →Processes and workflows are first-class citizens in the AST, which makes them easy to identify and analyze.
- →Nextflow scripts can be validated at a deeper level and errors can be caught earlier. This is because the space of possible syntax is reduced and Nextflow-specific concepts are represented directly in the AST.
The language server isn’t just better at catching errors—it’s stricter. It will report errors for things that are perfectly acceptable to the Nextflow CLI. Eventually, however, the Nextflow CLI will also adopt this strict syntax and it will become the only way to write Nextflow pipelines. That’s the “Nextflow → Groovy” dotted line in the above diagram and will allow the CLI and language server to be at parity with one another.
This strictness is the first step towards our goal of defining Nextflow as its own language. The stricter syntax enables the language server to provide better error messages, and in the long term, it will make Nextflow code more consistent and readable. Check out the new syntax reference and guide for fixing common errors with the new stricter syntax, and keep an eye out for future blogs that will describe these changes in detail.
Static analysis
Parsing is followed by several “passes” over the AST for things like name and type checking. These passes are collectively referred to as “static analysis” because they can be done without executing the code. The Nextflow CLI does very little static analysis, mostly because Groovy does not know anything about Nextflow. To do things like validate the workflow logic and construct the DAG, it must execute the code.
Meanwhile, the language server does a great deal of static analysis, not only for error checking, but also to support language features like hover hints, code completion, and goto definition. For example, one of the AST “passes” connects every process invocation to a process definition, so that when you hover over the process call, the language server can quickly look up the corresponding definition and show it in a tooltip.
The DAG preview is arguably the most advanced form of static analysis in the language server. It leverages data from all preceding stages—parsing, name checking, and process and workflow verification—to visualize the flow of data through the pipeline, from inputs to processes and workflows, and finally to outputs. As the DAG preview relies on all earlier analysis stages, it is only available when no errors are present.
The DAG preview is powerful because it relies only on static analysis:
- →It can be generated instantly, whereas the runtime DAG can only be generated by running the pipeline.
- →It captures all processes, even those that are conditionally executed, whereas the runtime DAG can only capture processes that are enabled by a particular parameter configuration.
- →It is concise and only shows the process and subworkflow calls in a particular workflow definition, whereas the runtime DAG can only show the entire pipeline and quickly becomes unreadable for larger pipelines.
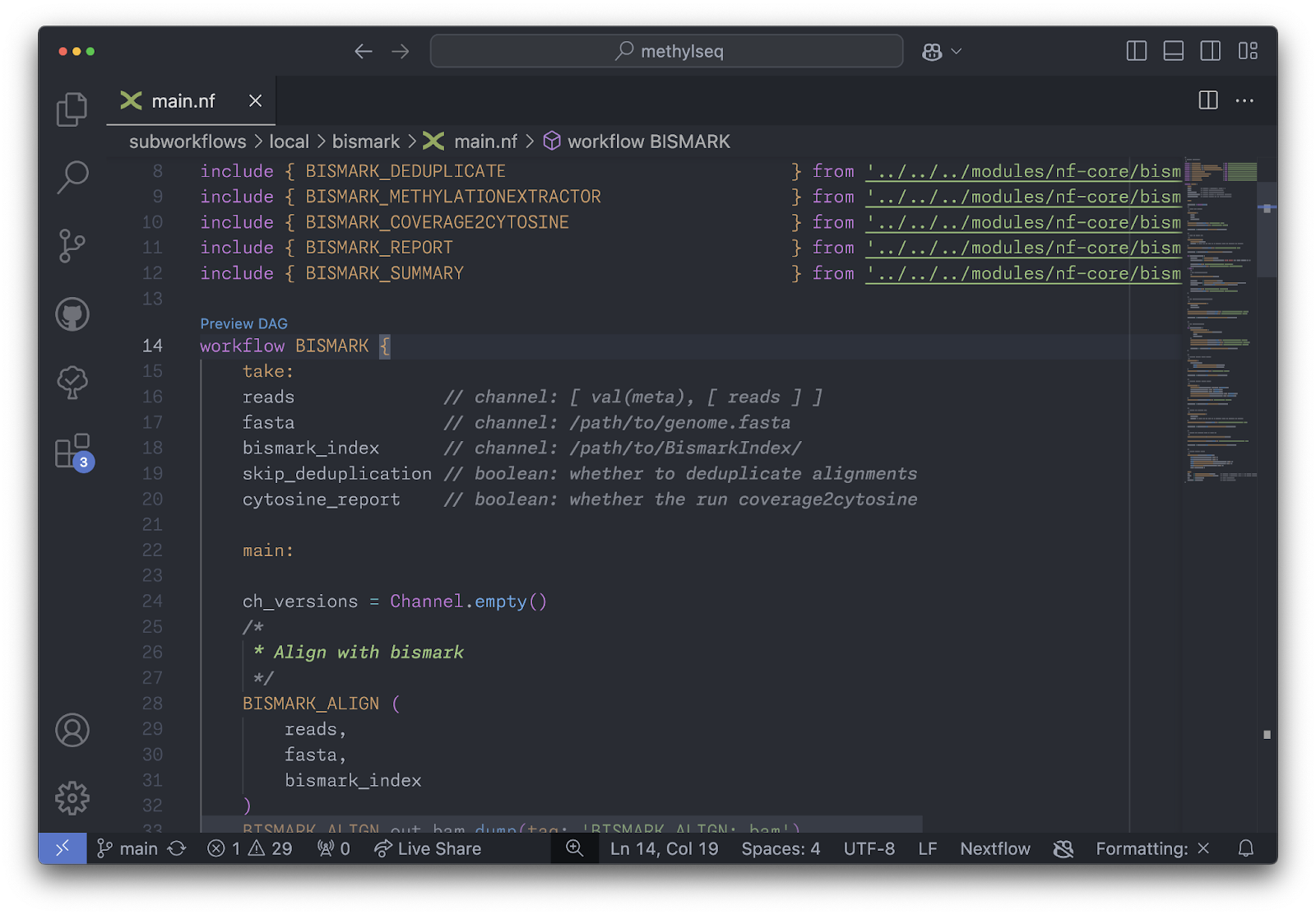
nf-core/methlyseq BISMARK subworkflow in VS Code.
The DAG preview is one of the crowning jewels of the language server and it was genuinely one of the most rewarding features to build. But it only scratches the surface of what is possible with static analysis. Many of the “magical” features that we plan to build into the Nextflow language in the coming years will almost certainly rely on some form of static analysis. Watch this space!
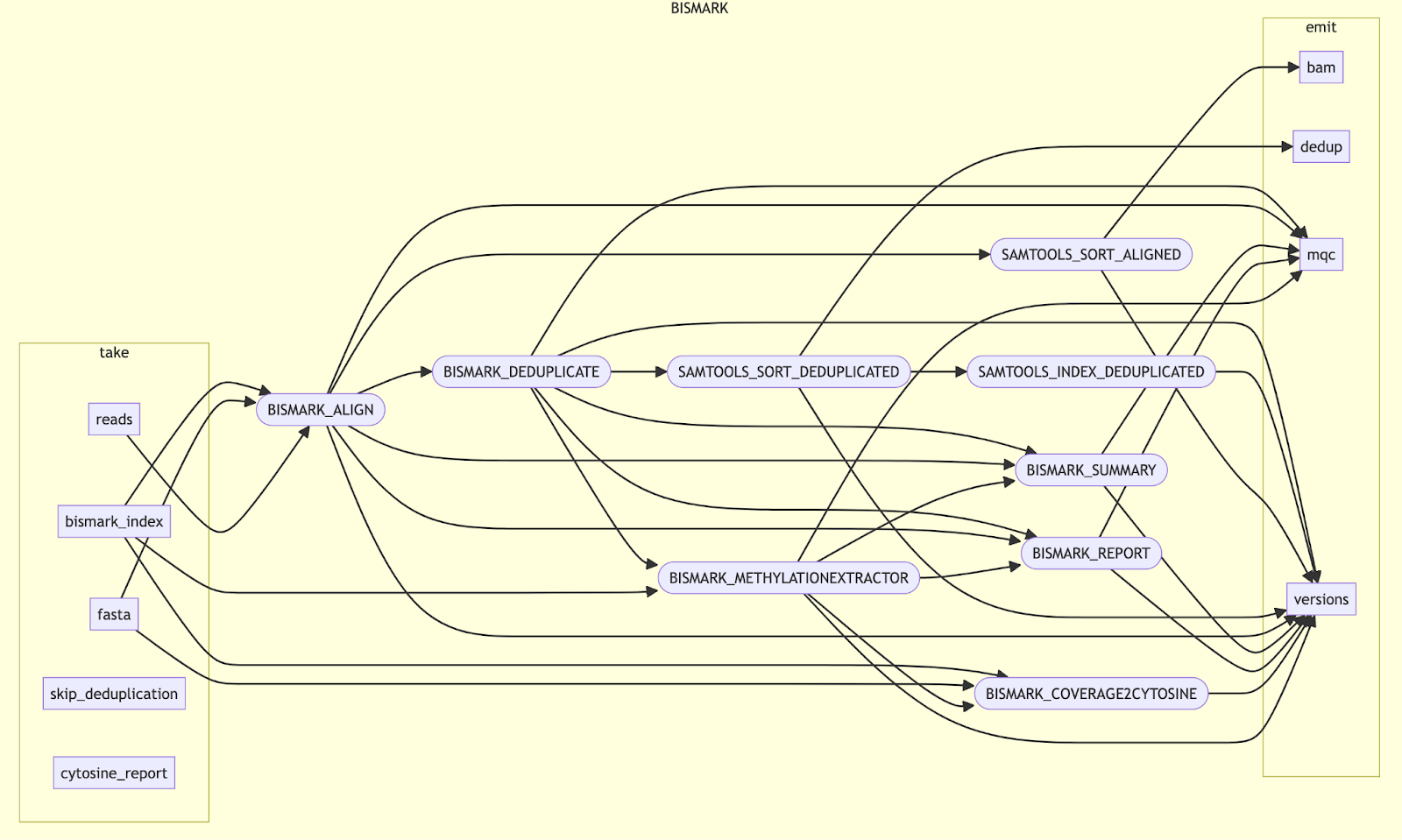
DAG of nf-core/methlyseq BISMARK subworkflow.
Beyond Groovy
Aside from restricting the syntax, a custom parser allows users to add new syntax outside of Groovy. Previously, any new language features in Nextflow had to be syntactically valid Groovy. But now, we need only be able to translate any new syntax to Groovy AST. This constraint is much looser, and it allows users to craft new syntax in a way that makes the most sense for Nextflow.
To demonstrate, here is a sneak preview of some of the new syntax we are considering for supporting static types in Nextflow:
Each of these examples is notable in that they are not valid Groovy syntax. The final syntax for static types might not look exactly like this, but the point is that we can now implement it in the “Nextflow way,” rather than trying to fit it into Groovy.
Acknowledgments
Building the Nextflow language server was greatly accelerated by a number of existing projects:
- →The Groovy compiler, which we used as the basis for the Nextflow parser and AST, and continues to serve as the compiler “backend” for Nextflow by handling the translation of Groovy AST to Java bytecode
- →The lsp4j library, which provides an easy-to-use Java API over all of the JSON-RPC requests in the Language Server Protocol
- →The Groovy language server, originally developed for the Moonshine IDE, which served as inspiration for how to integrate the Groovy compiler with lsp4j
We want to specifically acknowledge these projects for developing fundamental tooling and making it available for projects like this.
Release cycle
For now, the language server and VS Code extension are bundled together under the 1.x.x series of VS Code extension releases. They will continue to receive updates as we fix bugs and tweak various features.
In the future, we plan to decouple the language server from the VS Code extension and have it follow the Nextflow stable releases, such as 24.10.x, 25.04.x, 25.10.x, and so on. This way, each Nextflow stable release will have a corresponding language server release that understands the language rules for that specific version. The VS Code extension will download the appropriate version of the language server based on user preferences, allowing users to easily switch between different versions.
💡Note: The v1.x.x language server release can be used with older versions of Nextflow, but is recommended for Nextflow 24.10.x
Enhancing the Nextflow CLI
The language server's new parsing and error-checking functionality will be incorporated into the Nextflow CLI so that users have the same experience in the editor and on the command line. The new parser is stricter than the Nextflow CLI, so it will slowly be introduced as an opt-in feature that will eventually become the default.
The new parser will also be used to enhance the Nextflow CLI in other ways, including:
- →A new
checkcommand, equivalent to the language server’s error reporting, that allows users to bring the same level of error checking to automated environments such as CI - →A new
formatcommand, equivalent to the language server’s formatting command, that allows users to format code in automated environments such as CI - →An improved
inspectcommand that will show all processes and containers used in pipelines, including conditional processes that are only included under specific parameter configurations
Interested in finding out more?
In our next webinar, “A new era for Nextflow,” we will explore the powerful new Nextflow language server, discuss upcoming improvements to Nextflow syntax, and discuss the latest major version of the Nextflow VS Code extension.
💡Register for the webinar now