
Nextflow on BIG IRON: Twelve tips for improving the effectiveness of pipelines on HPC clusters
With all the focus on cloud computing, it's easy to forget that most Nextflow pipelines still run on traditional HPC clusters. In fact, according to our latest State of the Workflow 2023 community survey, 62.8% of survey respondents report running Nextflow on HPC clusters, and 75% use an HPC workload manager.1 While the cloud is making gains, traditional clusters aren't going away anytime soon.
Tapping cloud infrastructure offers many advantages in terms of convenience and scalability. However, for organizations with the capacity to manage in-house clusters, there are still solid reasons to run workloads locally:
- →Guaranteed access to resources. Users don't need to worry about shortages of particular instance types, Spot instance availability, or exceeding cloud spending caps.
- →Predictable pricing. Organizations are protected against price inflation and unexpected rate increases by capitalizing assets and depreciating them over time.
- →Reduced costs. Contrary to conventional wisdom, well-managed, highly-utilized, on-prem clusters are often less costly per core hour than cloud-based alternatives.
- →Better performance and throughput. While HPC infrastructure in the cloud is impressive, state-of-the-art on-prem clusters are still tough to beat.2
This article provides some helpful tips for organizations running Nextflow on HPC clusters.
The anatomy of an HPC cluster
HPC Clusters come in many shapes and sizes. Some are small, consisting of a single head node and a few compute hosts, while others are huge, with tens or even hundreds of host computers.
The diagram below shows the topology of a typical mid-sized HPC cluster. Clusters typically have one or more "head nodes" that run workload and/or cluster management software. Cluster managers, such as Warewulf, xCAT, NVIDIA Bright Cluster Manager, HPE Performance Cluster Manager, or IBM Spectrum Cluster Foundation, are typically used to manage software images and provision cluster nodes. Large clusters may have multiple head nodes, with workload management software configured to failover if the master host fails.
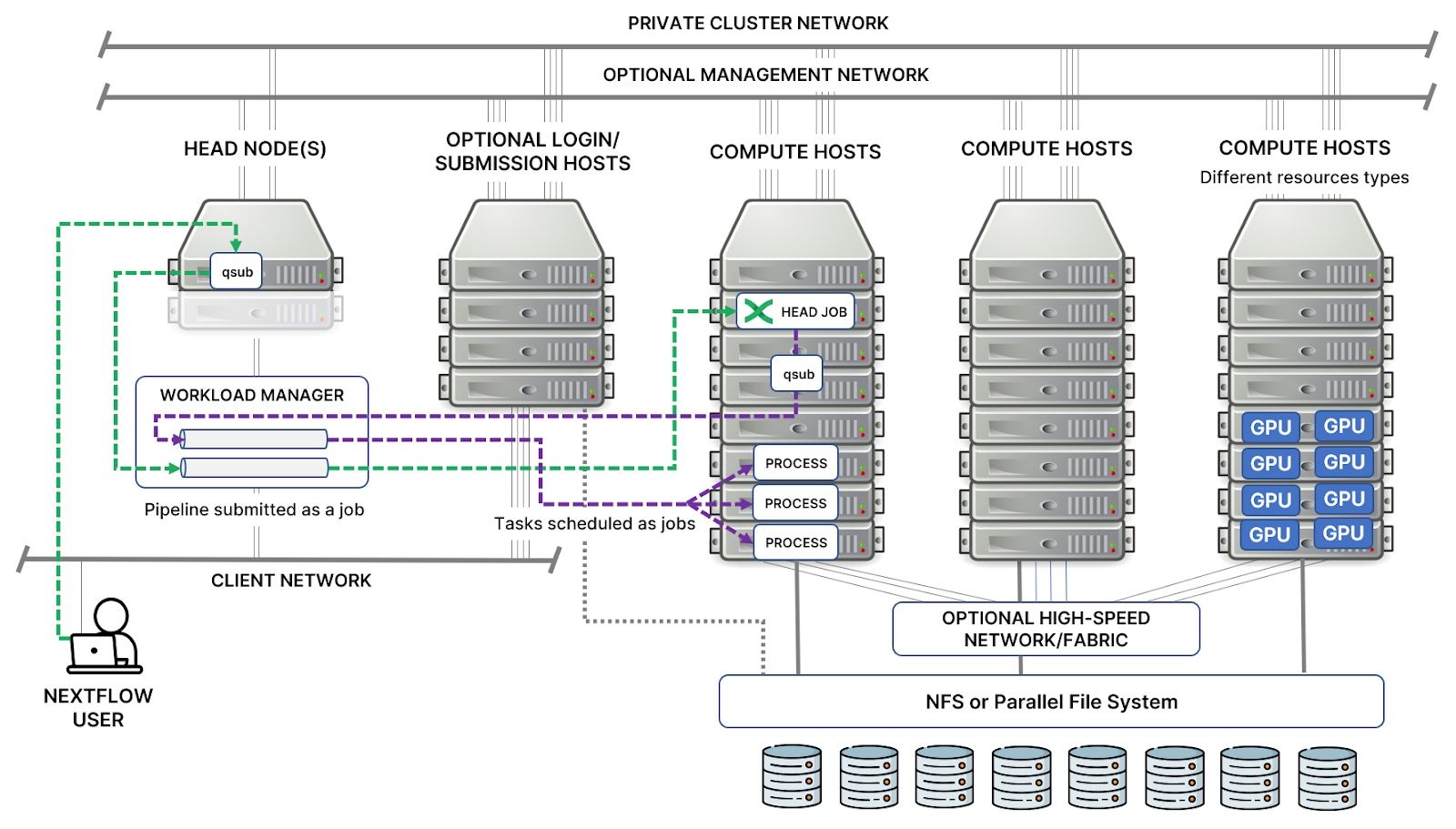
Large clusters may have dedicated job submission hosts (also called login hosts) so that user activity does not interfere with scheduling and management activities on the head node. In smaller environments, users may simply log in to the head node to submit their jobs.
Clusters are often composed of different compute hosts suited to particular workloads.3 They may also have separate dedicated networks for management, internode communication, and connections to a shared storage subsystem. Users typically have network access only to the head node(s) and job submission hosts and are prevented from connecting to the compute hosts directly.
Depending on the workloads a cluster is designed to support, compute hosts may be connected via a private high-speed 100 GbE or Infiniband-based network commonly used for MPI parallel workloads. Cluster hosts typically have access to a shared file system as well. In life sciences environments, NFS filers are commonly used. However, high-performance clusters may use parallel file systems such as Lustre, IBM Spectrum Scale (formerly GPFS), BeeGFS, or WEKA.
Learn about selecting the right storage architecture for your Nextflow pipelines.
HPC workload managers
HPC workload managers have been around for decades. Initial efforts date back to the original Portable Batch System (PBS) developed for NASA in the early 1990s. While modern workload managers have become enormously sophisticated, many of their core principles remain unchanged.
Workload managers are designed to share resources efficiently between users and groups. Modern workload managers support many different scheduling policies and workload types — from parallel jobs to array jobs to interactive jobs to affinity/NUMA-aware scheduling. As a result, schedulers have many "knobs and dials" to support various applications and use cases. While complicated, all of this configurability makes them extremely powerful and flexible in the hands of a skilled cluster administrator.
Some notes on terminology
HPC terminology can be confusing because different terms sometimes refer to the same thing. Nextflow refers to individual steps in a workflow as a "process". Sometimes, process steps spawned by Nextflow are also described as "tasks". When Nextflow processes are dispatched to an HPC workload manager, however, each process is managed as a"job" in the context of the workload manager.
HPC workload managers are sometimes referred to as schedulers. In this text, we use the terms HPC workload manager, workload manager, and scheduler interchangeably.
Nextflow and HPC workload managers
Nextflow supports at least 14 workload managers, not including popular cloud-based compute services. This number is even higher if one counts variants of popular schedulers. For example, the Grid Engine executor works with Altair® Grid Engine™ as well as older Grid Engine dialects, including Oracle Grid Engine (previously Sun Grid Engine), Open Grid Engine (OGE), and SoGE (son of Grid Engine). Similarly, the PBS integration works successors to the original OpenPBS project, including Altair® PBS Professional®, TORQUE, and Altair's more recent open-source version, OpenPBS.4 Workload managers supported by Nextflow are listed below:

Below we present some helpful tips and best practices when working with HPC workload managers.
Some best practices
1. Select an HPC executor
To ensure that pipelines are portable across clouds and HPC clusters, Nextflow uses the notion of executor to insulate pipelines from the underlying compute environment. A Nextflow executor determines the system where a pipeline is run and supervises its execution.
You can specify the executor to use in the nextflow.config file, inline in your pipeline code, or by setting the shell variable NXF_EXECUTOR before running a pipeline.
Executors are defined as part of the process scope in Nextflow, so in theory, each process can have a different executor. You can use the local executor to run a process on the same host as the Nextflow head job rather than dispatching it to an HPC cluster.
A complete list of available executors is available in the Nextflow documentation. Below is a handy list of executors for HPC workload managers.
2. Select a queue
Most HPC workload managers support the notion of queues. In a small cluster with a few users, queues may not be important. However, they are essential in large environments. Cluster administrators typically configure queues to reflect site-specific scheduling and resource-sharing policies. For example, a site may have a short queue that only supports short-running jobs and kills them after 60 seconds. A night queue may only dispatch jobs between midnight and 6:00 AM. Depending on the sophistication of the workload manager, different queues may have different priorities and access to queues may be limited to particular users or groups.
Workload managers typically have default queues. For example, normal is the default queue in LSF, while all.q is the default queue in Grid Engine. Slurm supports the notion of partitions that are essentially the same as queues, so Slurm partitions are referred to as queues within Nextflow. You should ask your HPC cluster administrator what queue to use when submitting Nextflow jobs.
Like the executor, queues are part of the process scope. The queue to dispatch jobs to is usually defined once in the nextflow.config file and applied to all processes in the workflow as shown below, or it can be set per-process.
Some organizations use queues as a mechanism to request particular types of resources. For example, suppose hosts with the latest NVIDIA A100 or K100 GPUs are in high demand. In that case, a cluster administrator may configure a particular queue called gpu_queue to dispatch jobs to those hosts and limit access to specific users. For process steps requiring access to GPUs, the administrator may require submitting jobs to this queue. This is why it is important to consult site-specific documentation or ask your cluster administrator which queues are available.
3. Specify process-level resource requirements
Depending on the executor, you can pass various resource requirements for each process/job to the workload manager. Like executors and queues, these settings are configured at the process level. Not all executors support the same resource directives, but the settings below are common to most HPC workload managers.
cpus – specifies the number of logical CPUs requested for a particular process/job. A logical CPU maps to a physical processor core or thread depending on whether hyperthreading is enabled on the underlying cluster hosts.
memory – different process steps/jobs will typically have different memory requirements. It is important to specify memory requirements accurately because the HPC schedulers use this information to decide how many jobs can execute concurrently on a host. If you overstate resource requirements, you are wasting resources on the cluster.
time – it is helpful to limit how much time a particular process or job is allowed to run. To avoid jobs hanging and consuming resources indefinitely, you can specify a time limit after which a job will be automatically terminated and re-queued. Time limits may also be enforced at the queue level behind the scenes based on workload management policies. If you have long-running jobs, your cluster administrator may ask you to use a particular queue for those Nextflow process steps to prevent jobs from being automatically killed.6
When writing pipelines, it is a good practice to consolidate per-process resource requirements in the nextflow.config file, and use process selectors to indicate what resource requirements apply to what process steps. For example, in the example below, processes will be dispatched to the Slurm cluster by default. Each process will require two cores, 4 GB of memory, and can run for no more than 10 minutes. For the foo and long-running bar jobs, process-specific selectors can override these default settings as shown below:
4. Take advantage of workload manager-specific features
Sometimes, organizations may want to take advantage of syntax specific to a particular workload manager. To accommodate this, most Nextflow executors provide a clusterOptions setting to inject one or more switches to the job submission command line specific to the selected workload manager (bsub, msub, qsub, etc).
These scheduler-specific commands can get very detailed and granular. They can apply to all processes in a workflow or only to specific processes. As an LSF-specific example, suppose a deep learning model training workload is a step in a Nextflow pipeline. The deep learning framework used may be GPU-aware and have specific topology requirements.
In this example, we specify a job consisting of two tasks where each task runs on a separate host and requires exclusive use of two GPUs. We also impose a resource requirement that we want to schedule the CPU portion of each CUDA job in physical proximity to the GPU to improve performance (on a processor core close to the same PCIe or NVLink connection, for example).
In addition to clusterOptions, several other settings in the executor scope can be helpful when controlling how jobs behave on an HPC workload manager.
5. Decide where to launch your pipeline
Launching jobs from a head node is common in small HPC clusters. Launching jobs from dedicated job submission hosts (sometimes called login hosts) is more common in large environments. Depending on the workload manager, the head node or job submission host will usually have the workload manager’s client tools pre-installed. These include client binaries such as sbatch (Slurm), qsub (PBS or Grid Engine), or bsub (LSF). Nextflow expects to be able to find these job submission commands on the Linux PATH.
Rather than launching the Nextflow driver job for a long-running pipeline from the head node or a job submission host, a better practice is to wrap the Nextflow run command in a script and submit the entire workflow as a job. An example using LSF is provided below:
The specifics will depend on the cluster environment and how the environment is configured. For this to work, the job submission commands must also be available on the execution hosts to which the head job is dispatched. This is not always the case, so you should check with your HPC cluster administrator.
Depending on the workload manager, check your queue or cluster configuration to ensure that submitted jobs can spawn other jobs and that you do not bump up against hard limits. For example, Slurm by default allows a job step to spawn up to 512 tasks per node by default.7
6. Limit your heap size
Setting the JVM’s max heap size is another good practice when running on an HPC cluster. The Nextflow runtime runs on top of a Java virtual machine which by design, tries to allocate as much memory as possible. To avoid this, specify the maximum amount of memory that can be used by the Java VM using the -Xms and -Xmx Java flags.
These can be specified using the NXF_OPTS environment variable.
The -Xms flag specifies the minimum heap size, and -Xmx specifies the maximum heap size. In the example above, the minimum heap size is set to 512 MB, which can grow to a maximum of 8 GB. You will need to experiment with appropriate values for each pipeline to determine how many concurrent head jobs you can run on the same host.
For more information about memory management with Java, consult this Oracle documentation regarding tuning JVMs.
7. Use the scratch directive
Nextflow requires a shared file system path as a working directory to allow the pipeline tasks to share data with each other. When using this model, a common practice is to use the node's local scratch storage as the working directory. This avoids cluster nodes needing to simultaneously read and write files to a shared network file system, which can become a bottleneck.
Nextflow implements this best practice which can be enabled by adding the following setting in your nextflow.config file.
By default, if you enable process.scratch, Nextflow will use the directory pointed to by $TMPDIR as a scratch directory on the execution host.
You can optionally specify a specific path for the scratch directory as shown:
When the scratch directive is enabled, Nextflow:
- →Creates a unique directory for process execution in the supplied scratch directory.
- →Creates a symbolic link in the scratch directory for each input file in the shared work directory required for job execution.
- →Runs the job using the local scratch path as the working directory.
- →Copies output files to the job's shared work directory on the shared file system when the job is complete.
Scratch storage is particularly beneficial for process steps that perform a lot of file system I/O or create large numbers of intermediate files.
To learn more about Nextflow and how it works with various storage architectures, including shared file systems, check out our recent article Selecting the right storage architecture for your Nextflow pipelines.
8. Launch pipelines in the background
If you are launching your pipeline from a login node or cluster head node, it is useful to run pipelines in the background without losing the execution output reported by Nextflow. You can accomplish this by using the -bg switch in Nextflow and redirecting stdout to a log file as shown:
This frees up the interactive command line to run commands such as squeue (Slurm) or qstat (Grid Engine) to monitor job execution on the cluster. It is also beneficial because it prevents network connection issues from interfering with pipeline execution.
Nextflow has rich terminal logging and uses ANSI escape codes to update pipeline execution counters interactively as the pipeline runs. If you are logging output to a file as shown above, it is a good idea to disable ANSI logging using the command line option -ansi-log false or the environment variable NXF_ANSI_LOG=false. ANSI logging can also be disabled when wrapping the Nextflow head job in a script and launching it as a job managed by the workload manager as explained above.
9. Retry failing jobs after increasing resource allocation
Getting resource requirements such as cpu, memory, and time is often challenging since resource requirements can vary depending on the size of the dataset processed by each job step. If you request too much resource, you end up wasting resources on the cluster and reducing the effectiveness of the compute environment for everyone. On the other hand, if you request insufficient resources, process steps can fail.
To address this problem, Nextflow provides a mechanism that allows you to modify the amount of computing resources requested in the case of a process failure on the fly and attempt to re-execute it using a higher limit. For example:
You can manage how many times a job can be retried and specify different behaviors depending on the exit error code. You will see this automated mechanism used in many production pipelines. It is a common practice to double the resources requested after a failure until the job runs successfully.
For sites running Nextflow Tower, Tower has a powerful resource optimization facility built in that essentially learns per-process resource requirements from previously executed pipelines and auto-generates resource requirements that can be placed in a pipeline's nextflow.config file. By using resource optimization in Tower, pipelines will request only the resources that they actually need. This avoids unnecessary delays due to failed/retried jobs and also uses the shared cluster more efficiently.
Tower resource optimizations works with all HPC workload managers as well as popular cloud services. You can learn more about resource optimization in the article Optimizing resource usage with Nextflow Tower.
10. Cloud Bursting
Cloud bursting is a configuration method in hybrid cloud environments where cloud computing resources are used automatically whenever on-premises infrastructure reaches peak capacity. The idea is that when sites run out of compute capacity on their local infrastructure, they can dynamically burst additional workloads to the cloud.
With its built-in support for cloud executors, Nextflow handles bursting to the cloud with ease, but it is important to remember that large HPC sites run other workloads beyond Nextflow pipelines. As such, they often have their own bursting solutions tightly coupled to the workload manager.
Commercial HPC schedulers tend to have facilities for cloud bursting built in. While there are many ways to enable burstings, and implementations vary by workload manager, a few examples are provided here:
- →Open source Slurm provides a native mechanism to burst workloads to major cloud providers when local cluster resources are fully subscribed. To learn more, see the Slurm Cloud Scheduling Guide.
- →IBM Spectrum LSF provides a cloud resource connector enabling policy-driven cloud bursting to various clouds. See the IBM Spectrum LSF Resource Connector documentation for details.
- →Altair PBS Professional also provides sophisticated support for cloud bursting to multiple clouds, with cloud cost integration features that avoid overspending in the cloud. See PBS Professional 2022.1.
- →Adaptive Computing offers Moab Cloud/NODUS Cloud Bursting, a commercial offering that works with an extensive set of resource providers including AliCloud, OCI, OpenStack, VMware vSphere, and others.
Data handling makes cloud bursting complex. Some HPC centers deploy solutions that provide a consistent namespace where on-premises and cloud-based nodes have a consistent view of a shared file system.
If you are in a larger facility, it's worth having a discussion with your HPC cluster administrator. Cloud bursting may be handled automatically for you. You may be able to use the executor associated with your on-premises workload manager, and simply point your workloads to a particular queue. The good news is that Nextflow provides you with tremendous flexibility.
11. Fusion file system
Traditionally, on-premises clusters have used a local shared file system such as NFS or Lustre. The new Fusion file system provides an alternative way to manage data.
Fusion is a lightweight, POSIX-compliant file system deployed inside containers that provides transparent access to cloud-based object stores such as Amazon S3. While users running pipelines on local clusters may not have considered using cloud storage, doing so has some advantages:
- →Cloud object storage is economical for long-term storage.
- →Object stores such as Amazon S3 provided virtually unlimited capacity.
- →Many reference datasets in life sciences already reside in cloud object stores.
In cloud computing environments, Fusion FS has demonstrated that it can improve pipeline throughput by up to 2.2x and reduce long-term cloud storage costs by up to 76%. To learn more about Fusion file systems and how it works, you can download the whitepaper Breakthrough performance and cost-efficiency with the new Fusion file system.
Recently, Fusion support has been added for selected HPC workload managers including Slurm, IBM Spectrum LSF, and Grid Engine. This is an exciting development as it enables on-premises cluster users to seamlessly run workload locally using cloud-based storage with minimal configuration effort.
12. Additional configuration options
There are several additional Nextflow configuration options that are important to be aware of when working with HPC clusters. You can find a complete list in the Netflow documentation in the Scope executor section.
queueSize – The queueSize parameter is optionally defined in the nextflow.config file or within a process and defines how many Nextflow processes can be queued in the selected workload manager at a given time. By default, this value is set to 100 jobs. In large sites with multiple users, HPC cluster administrators may limit the number of pending or executing jobs per user on the cluster. For example, on an LSF cluster, this is done by setting the parameter MAX_JOBS in the lsb.users file to enforce per user or per group slot limits. If your administrators have placed limits on the number of jobs you can run, you should tune the queueSize parameter in Nextflow to match your site enforced maximums.
submitRateLimit – Depending on the scheduler, having many users simultaneously submitting large numbers of jobs to a cluster can overwhelm the scheduler on the head node and cause it to become unresponsive to commands. To mitigate this, if your pipeline submits a large number of jobs, it is a good practice to throttle the rate at which jobs will be dispatched from Nextflow. By default the job submission rate is unlimited. If you wanted to allow no more than 50 jobs to be submitted every two minutes, set this parameter as shown:
jobName – Many workload managers have interactive web interfaces or downstream reporting or analysis tools for monitoring or analyzing workloads. A few examples include Slurm-web, MOAB HPC Suite (MOAB and Torque), Platform Management Console (for LSF), Spectrum LSF RTM, and Altair® Access™.
When using these tools, it is helpful to associate a meaningful name with each job. Remember, a job in the context of the workload manager maps to a process or task in Nextflow. Use the jobName property associated with the executor to give your job a name. You can construct these names dynamically as illustrated below so the job reported by the workload manager reflects the name of our Nextflow process step and its unique ID.
You will need to make sure that generated name matches the validation constraints of the underlying workload manager. This also makes troubleshooting easier because it allows you to cross reference Nextflow log files with files generated by the workload manager.
The bottom line
In addition to supporting major cloud environments, Nextflow works seamlessly with a wide variety of on-premises workload managers. If you are fortunate enough to have access to large-scale compute infrastructure at your facility, taking advantage of these powerful HPC workload management integrations is likely the way to go.
1 While this may sound like a contradiction, remember that HPC workload managers can also run in the cloud.
2 A cloud vCPU is equivalent to a thread on a multicore CPU, and HPC workloads often run with hyperthreading disabled for the best performance. As a result, you may need 64 vCPUs in the cloud to match the performance of a 32-core processor SKU on-premises. Similarly, interconnects such as Amazon Elastic Fabric Adapter (EFA) deliver impressive performance. However, even with high-end cloud instance types, its 100 Gbps throughput falls short compared to interconnects such as NDR InfiniBand and HPE Cray Slingshot, delivering 400 Gbps or more.
3 While MPI parallel jobs are less common in Nextflow pipelines, sites may also run fluid dynamics, computational chemistry, or molecular dynamics workloads using tools such as NWChem or GROMACS that rely on MPI and fast interconnects to facilitate efficient inter-node communication.
4 Altair’s open-source OpenPBS is distinct from the original OpenPBS project released in 1998 of the same name.
5 MOAB HPC is a commercial product offered by Adaptive Computing. Its scheduler is based on the open source Maui scheduler.
6 For some workload managers, knowing how much time a job is expected to run is considered in scheduling algorithms. For example, suppose it becomes necessary to preempt particular jobs when higher priority jobs come along or because of resource ownership issues. In that case, the scheduler may take into account actual vs. estimated runtime to avoid terminating long-running jobs that are closed to completion.
7 MaxTasksPerNode setting is configurable in the slurm.conf file.
8 Jobs that request large amounts of resource often pend in queues and take longer to schedule impacting productivity as there may be fewer candidate hosts available that meet the job’s resource requirement.