
Seqera is often approached for guidance on how to streamline the execution of workflows in production environments. For example, bioinformaticians want to automatically execute a pipeline as data arrives off a sequencer or would like to integrate Nextflow Tower into a broader customer-facing application.
While each answer varies based on the specific needs of the customer, they all receive the same advice: Leverage Nextflow Tower’s event-driven automation capabilities to invoke pipelines rather than relying on humans.
Staff have many responsibilities
Employees are busy and have many competing demands. Businesses that rely on manual pipeline invocation make themselves dependent upon staff to:
- →Stay informed when new input data becomes available.
- →Curate sample metadata in a timely fashion.
- →Set aside time to manually trigger pipelines.
Even under ideal conditions, several hours or days may pass between the arrival of input data and launching the downstream analysis pipeline. Additionally, human intervention can be expensive! This is time and money spent waiting for results rather than furthering business objectives.
Streamline pipeline invocation using Nextflow Tower CLI & Datasets
With the recent release of the Nextflow Tower CLI and Nextflow Tower Datasets, it has never been easier to implement automation logic that will invoke a pipeline as soon as new data becomes available.
Keep reading to see how you can combine cloud native tooling with these new features to build a solution within your own Tower environment.
Tutorial Overview
This tutorial will cover how to create an automation solution that performs the following steps:
- →Detect when new data is available for processing.
- →Embed the new data as a sample sheet into a Nextflow Tower Dataset object.
- →Invoke a workflow which uses the Dataset as its input.
Nextflow workflow management systems
We will use these Seqera solutions:
Cloud vendor tooling
Cloud tooling will vary depending on your provider. This tutorial is built in AWS and uses:
- →Sample sheet storage via S3.
- →New file notification via S3 Event Notifications.
- →New file notification processing logic via Lambda.
- →Container storage via ECR.
- →Secrets management via AWS Secrets Manager.
- →Parameter management via AWS Systems Manager.
- →Logging capabilities via Lambda integration with CloudWatch.
- →Permission management via IAM.
Component Diagram
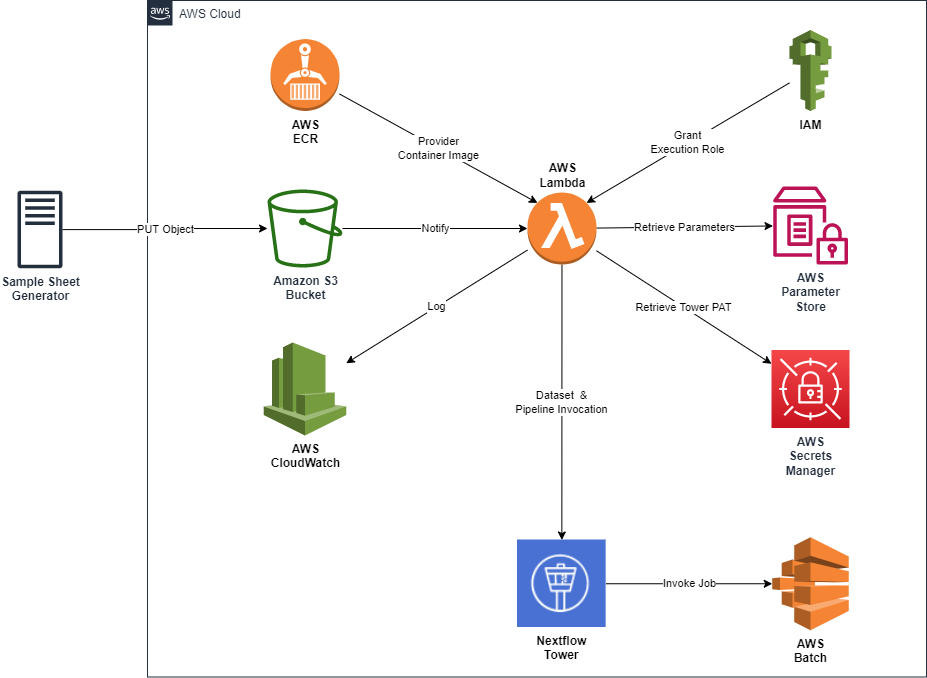
Prerequisites
To complete this activity, please ensure you have the following tools, permissions, and Tower artifacts:
- →A locally installed Docker instance.
- →A locally installed Python 3.9 instance.
- →A locally configured AWS CLI with the ability to:
- →Create and modify IAM Roles & Policies.
- →Create and modify Secrets Manager secrets.
- →Create and modify Systems Manager Parameter Store parameters.
- →Create and modify ECR repositories.
- →Push and pull ECR images.
- →A Tower Cloud account or Tower Enterprise instance with:
- →A valid Personal Access Token.
- →A Workspace with Administrator rights.
- →A configured nf-core/rnaseq pipeline with a unique name.
Code Repository
All the materials used to generate the solution can be found at https://github.com/seqeralabs/datasets-automation-blog.
Prepare Supporting AWS Services
Create the supporting AWS infrastructure upon which our automation solution relies.
S3
- →Create an S3 Bucket in your default Region, and populate it with a
lambda_tutorialfolder.$ aws s3api create-bucket \
--bucket BUCKET_NAME
$ aws s3api put-object \
--bucket BUCKET_NAME \
--key lambda_tutorial/
IAM
The Lambda function requires an IAM Role to interact with other AWS Services. This role is transparently assumed each time the function is invoked on the AWS platform, with user credentials being made available as environment variables inside the container.
We will allow the Role to be assumed by the Lambda Service, and also allow actors linked to your AWS Account to facilitate local testing.
- →Create trust_policy.json.
Replace the placeholder with your own AWS Account number.
Create lambda_tutorial_all_permissions.json. Replace the placeholders with your own S3 Bucket, AWS Region, and AWS Account number. - →Create the IAM Role
lambda_tutorial.$ aws iam create-role \
--role-name lambda_tutorial \
--assume-role-policy-document file://trust_policy.json
Grant thelambda_tutorialRole permissions via an inline policy.$ aws iam put-role-policy \
--role-name lambda_tutorial \
--policy-name lambda_tutorial_all_permissions \
--policy-document file://lambda_tutorial_all_permissions.json
Secrets Manager
- →Create an AWS Secrets Manager entry for your Tower PAT.
$ aws secretsmanager create-secret \
--name lambda_tutorial/tower_PAT \
--secret-string <your_pat_here>
Systems Manager Parameter Store
- →Create a parameter for your Tower instance’s API URL.
# NOTE: If using your own Tower instance, your API pattern is:
# `https://YOUR_URL/api`. The CLI will try to auto-resolve URLs
# passed to it, so we need to temporarily set this to false.
$ aws configure set cli_follow_urlparam false
$ aws ssm put-parameter \
--name "/lambda_tutorial/tower_api_endpoint" \
--type "String" \
--value "https://api.tower.nf" \
--overwrite
$ aws configure set cli_follow_urlparam true - →Create a parameter for the Workspace ID where your Dataset will be created.
$ aws ssm put-parameter \
--name "/lambda_tutorial/workspace_id" \
--type "String" \
--value "YOUR_WORKSPACE_ID" \
--overwrite - →Create a parameter identifying the pipeline to invoke once the Dataset is created.
$ aws ssm put-parameter \
--name "/lambda_tutorial/target_pipeline_name" \
--type "String" \
--value "YOUR_PIPELINE_NAME" \
--overwrite - →Create a parameter that specifies the S3 bucket prefix where sample sheets will be stored.
# NOTE: Must include trailing '/'
$ aws ssm put-parameter \
--name "/lambda_tutorial/s3_root_prefix" \
--type "String" \
--value "lambda_tutorial/" \
--overwrite - →Create a parameter to identify the file extensions that represent sample sheet files.
$ aws ssm put-parameter \
--name "/lambda_tutorial/samplesheet_file_types" \
--type "String" \
--value "csv,tsv" \
--overwrite - →Create a parameter that specifies the desired function logging level.
# Note: The provided code is DEBUG by default.
# Set a stricter logging level in production to avoid secrets in CloudWatch logs.
$ aws ssm put-parameter \
--name "/lambda_tutorial/logging_level" \
--type "String" \
--value "DEBUG" \
--overwrite
ECR Registry
- →Create the
lambda_tutorialrepository.$ aws ecr create-repository \
--repository-name lambda_tutorial
Authenticate your Docker instance with the repository. - →
$ aws ecr get-login-password \
--region YOUR_REGION | docker login \
--username AWS \
--password-stdin YOUR-AWS-ACCOUNT.dkr.ecr.YOUR-REGION.amazonaws.com
Create Lambda Function Code and Container
With the supporting AWS Services created, we can now create the Lambda function and underlying Docker image.
Create The Lambda Function Code
- →Create app.py.
This is the code that will be executed each time your Lambda Function is invoked.
High-Level Logic
The main logic resides in the handler function and executes as follows:
- →Determine whether execution is on the local machine or the Lambda Service, and generate a session appropriately.
- →Retrieve and set SSM Parameter Store values as environment variables.
- →Evaluate whether the new file is a sample sheet which must be further processed.
- →Retrieve and set Secret Manager secrets as local environment variables.
- →Download the sample sheet from S3.
- →Create a Dataset in Tower.Invoke a pipeline in Tower specifying the newly-created sample sheet as input.
Assumptions Made In Code
The code was created with the following assumptions:
- →A Tower Dataset comprises only a single sample sheet.
- →A new Dataset should be created every time rather than creating a new version of a pre-existing Dataset.
- →A Tower Dataset should mirror the name of the sample sheet.
- →All supplied sample sheets have a header.
- →It was acceptable to hardcode the execution role and SSM parameter names in the handler function in return for simpler execution logic.
- →Use of
DEBUGlogging level by default was acceptable for facilitating initial solution stand-up.
Notable Constraint: Lambda Retry
The Lambda execution framework complicates how one can cease processing an event mid-transaction, especially when using a procedural programming helper function style.
Lambda will stop processing an event once return is invoked from the handler function. This terminates the handling of the current event, while allowing the Python process itself to remain alive and ready to process the next notification event should it occur before the container is torn down.
In the case of our function, sometimes we want it to retry processing our event (e.g. if a network hiccup blocked a remote call) whereas we don’t want Lambda to retry an event when we have deliberately stopped processing (e.g. we determine that the file type is not an in-scope sample sheet file and therefore does not require further processing).
To balance both needs, the provided code raises two types of exceptions:
- →A custom
CeaseEventProcessingexception is thrown when we deliberately decide that a retry should not occur. This exception is caught and processed within the handler function in a way that does not trigger Lambda’s in-built retry mechanism. - →A generic Exception is used for everything else. This exception is not caught and handled in the handler function, and can therefore trigger the Lambda retry mechanism.
Create Lambda Function Container Image
I’ve chosen debian:stable-slim as our base image given its compactness and ubiquity. Package installation is minimal, but the use of an alternative base rather than the standard Lambda image requires additional steps to install the Python Runtime Interface Client and configure the container’s Entrypoint to emulate the Lambda Service when run locally.
- →Create entry_script.sh. This script emulates Lambda if run on your local machine or invokes the real runtime if executed within the AWS Service.
- →Create requirements.txt. This identifies all the Python packages that must be installed to support our Lambda function.
- →Create the Dockerfile.
Create And Test Your Docker Image
With the the code artefacts complete, generate a local Docker and smoke test the application before conducting further testing in your AWS Account.
When testing locally, mount the credentials from your locally-configured AWS CLI into the container. The code will use the default AWS profile to assume the lambda_tutorial IAM Role for execution permissions.
- →Create the Docker image.
$ docker build --tag lambda_tutorial:v1.0 . - →Create test event(s) to verify bucket source, bucket prefix, and file types logic.
- →If using the provided test events, be sure to replace
YOUR_AWS_REGIONandYOUR_S3_BUCKETwith your own values.
For positive test cases, ensure there is a file in your S3 bucket that matches the event details so that your function has a file to retrieve.
Run the local container instance.$ docker run --rm -it -v ~/.aws:/root/.aws:ro -p 9000:8080 lambda_tutorial:v1.0 - →Submit transactions to the local instance.
$ curl -XPOST "http://localhost:9000/2015-03-31/functions/function/invocations" \
-d @PATH_TO_YOUR_JSON_TEST_EVENT
Push Your Image to ECR
Once you are satisfied your code is working properly, push the image to ECR.
- →Retag the local image.
$ docker tag lambda_tutorial:v1.0 YOUR_ECR_REPO/lambda_tutorial:latest - →Push the image to your ECR.
$ docker push YOUR_ECR_REPO/lambda_tutorial:latest
Instantiate Function On AWS Lambda Service
Create the Function
- →Log in to the AWS Lambda Console. Click the Create function button.
On the Create function screen:
- Specify that the source will be a Container image.
- Set Function name to
lambda_tutorial. - Set
Container image URIto your newly-uploaded image. - Set Execution Role to Use an existing role.
- Select lambda_tutorial from the Existing Role dropdown.
- Click Create Function.
Add S3 Trigger
Once you’ve created the function, add a configuration for it to receive events from S3.
- →On your function’s main dashboard, Click + Add trigger.
- →On the Add Trigger screen:
1. Select S3 as the event source.
2. Specify the source Bucket.
3. SpecifyPUTas the Event type.
4. Specify lambda_tutorial/ as the Prefix.
5. Click the Add button.
Modify Configuration Values
The code is executed sequentially, must make several network calls, and has received minimal optimization. Based on previous testing rounds conducted in the AWS Lambda environment, the end-to-end process needs approximately 200MB of RAM and 10 seconds of execution time. As a result, the default Lambda configuration values need to be modified to ensure that our function can execute successfully.
- →We will err on the side of caution and initially overprovision RAM at 250MB. You can adjust this later once you see how your own function behaves.We will increase the default 3 second timeout to a generous 30 seconds. This is also overprovisioned but ensures smooth testing. You can adjust this later once you see how your own function behaves.
- →Edit General configuration.
1. Change Memory to 250 MB.
2. Change Timeout to 30 seconds.
Test Your Function
- →Port your local test events to the Lambda Service.
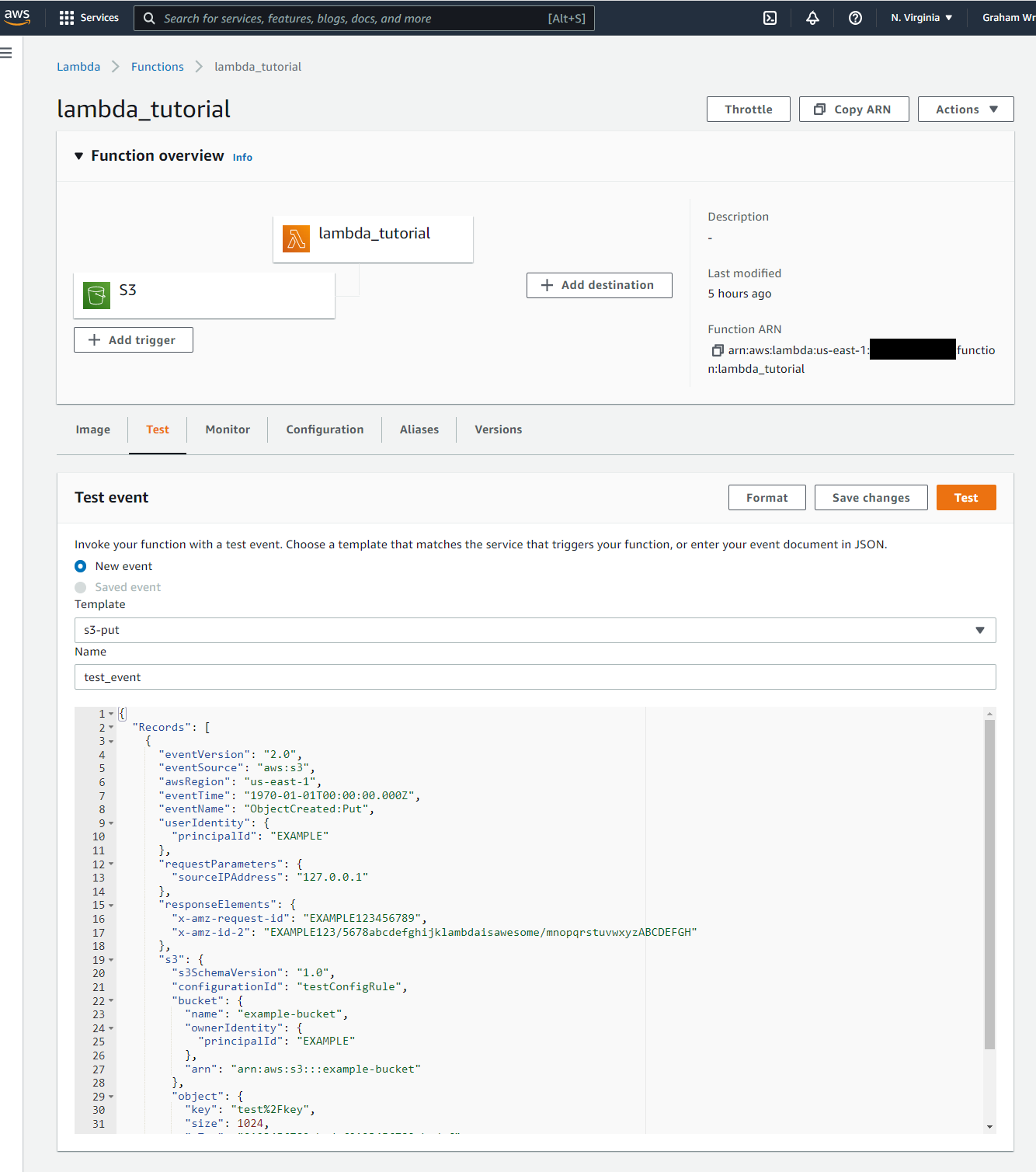
- →Invoke a known good test event and confirm it runs successfully.
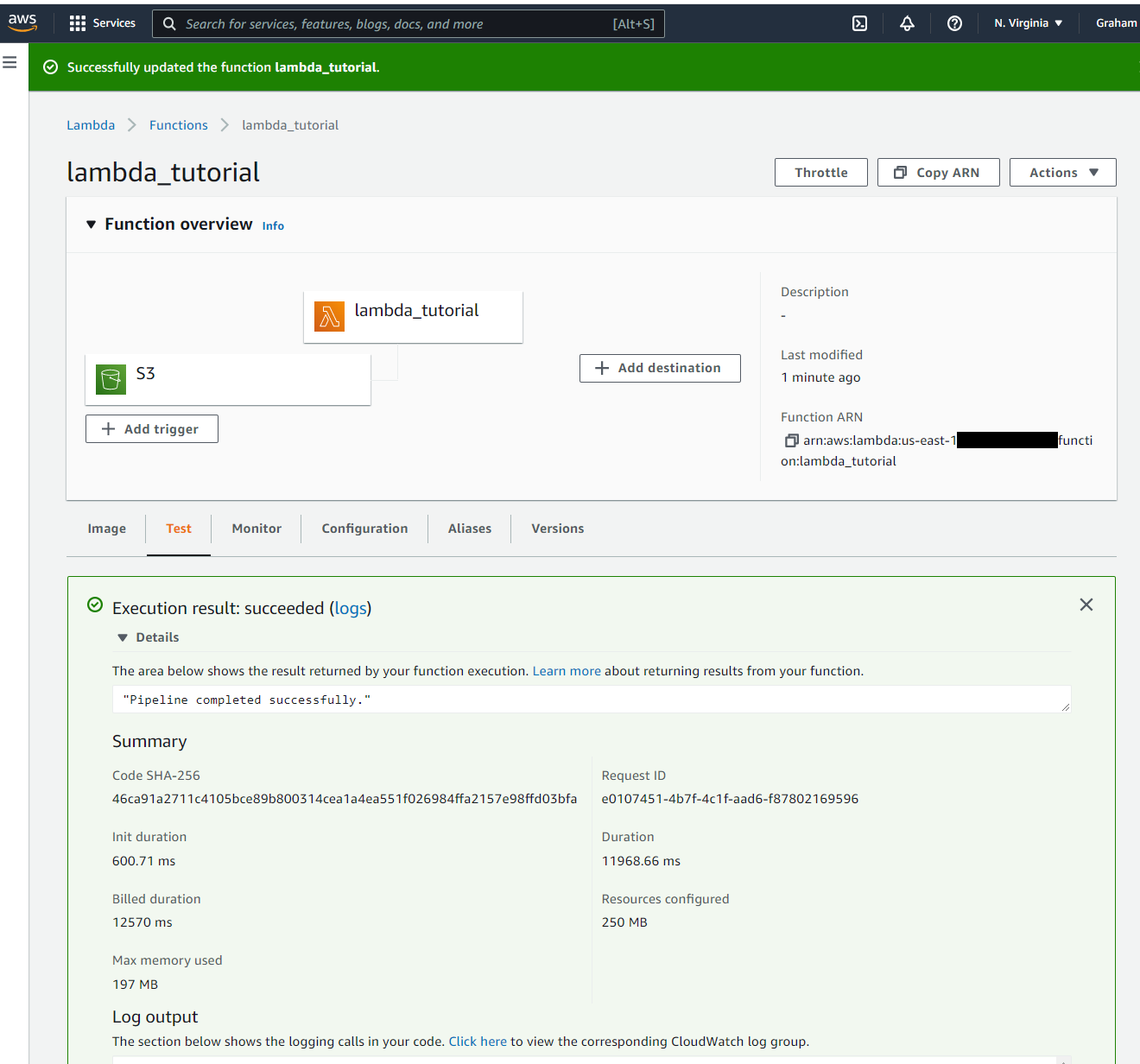
- →Check that a Dataset is created in Tower.
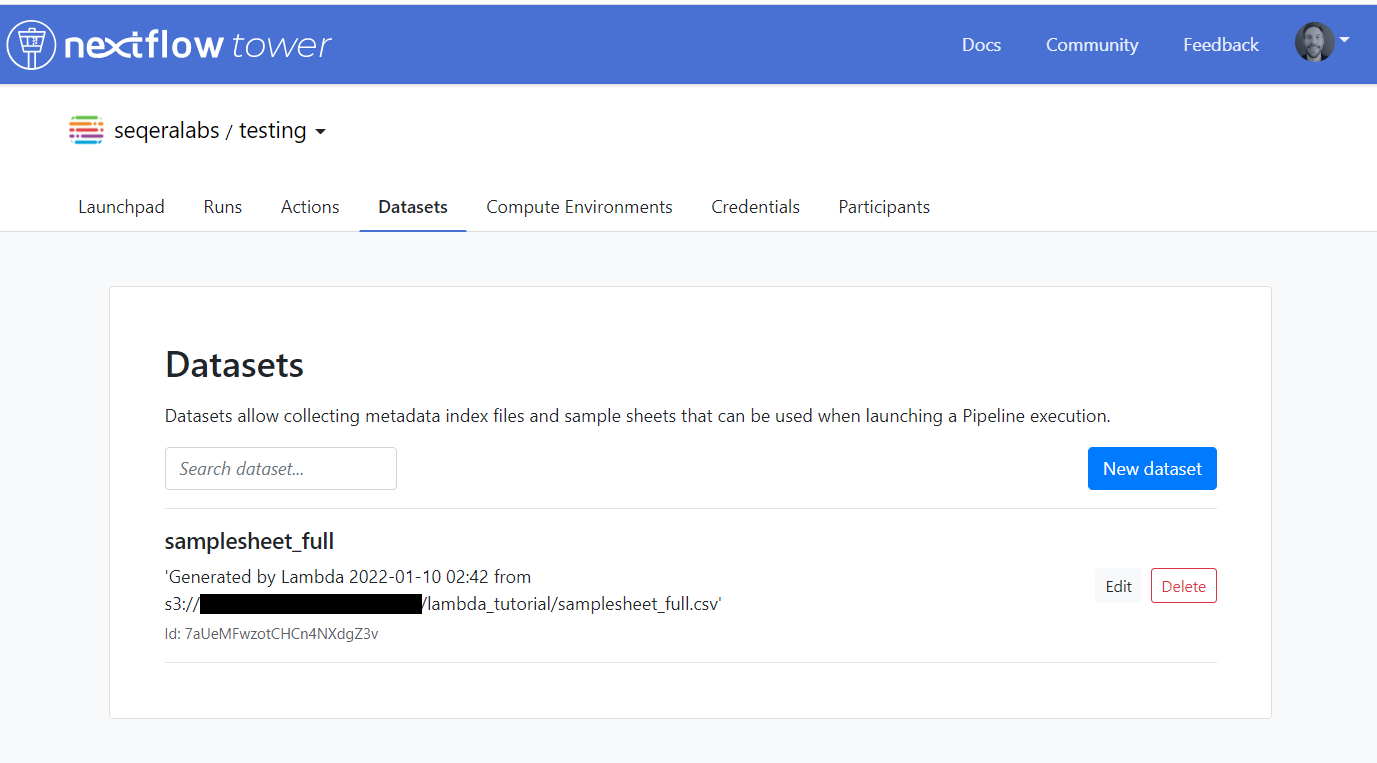
- →Check that your pipeline was automatically invoked in Tower.
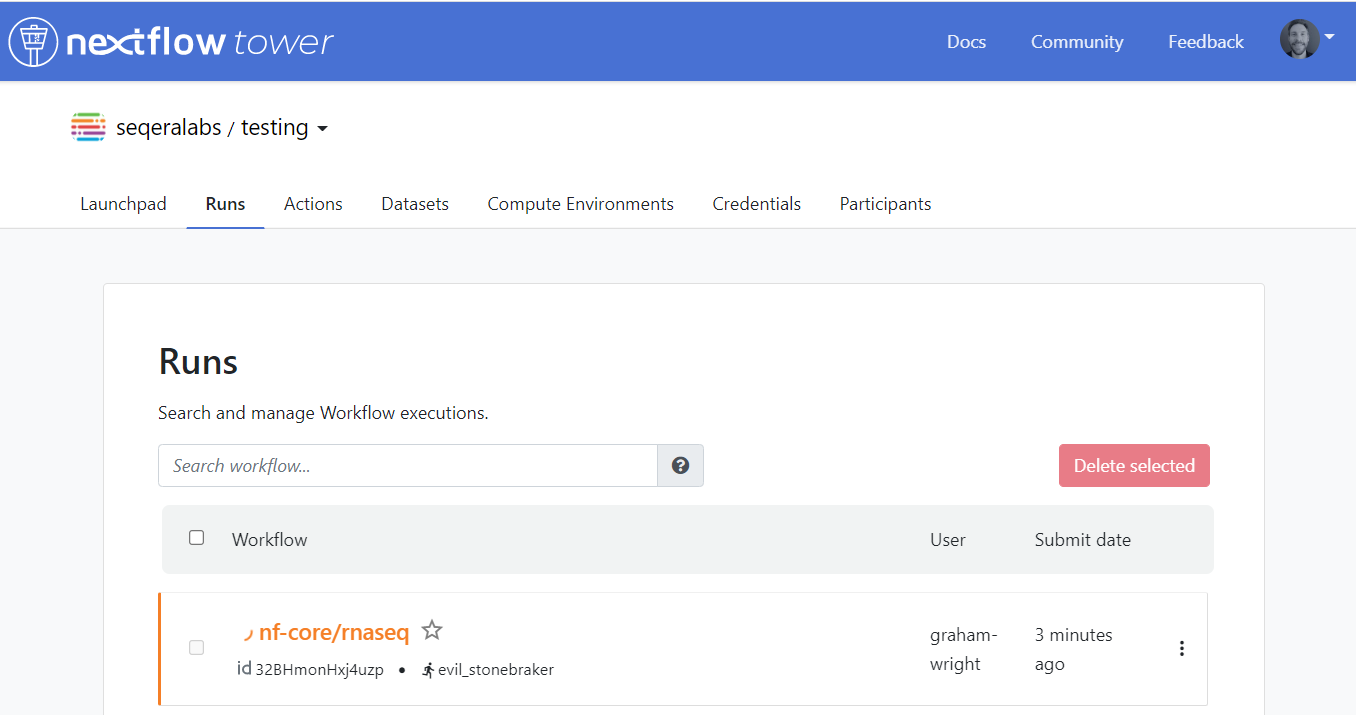
- →Terminate the Run and delete the Dataset.
Estimate Costs
Based on the data generated from the test runs, we can now calculate the cost of the average run:
- →In the us-east-1 Region, a Lambda function using 250 MB RAM is charged ~$0.000000004 per 1ms of execution.
- →Our function took 12570 ms to complete.Total cost of run = $0.000000004 \* 12570 = $0.00005
As you can see, the cost of execution is miniscule: ~$1 will pay for 20,000 executions!
Conduct a Real-World Invocation
With the function successfully tested and deployed to the AWS Lambda Service, you can now invoke your automation by depositing a file in your S3 bucket!
- →Download a test sample sheet for the nf-core/rnaseq pipeline.
- →Copy the file into your S3 Bucket, ensuring it is within the prefix specified in the SSM
/lambda_tutorial/s3_root_prefixparameter.$ aws s3 cp samplesheet_full.csv s3://YOUR_S3_BUCKET/IN_SCOPE_PREFIX/samplesheet_full.csv
Check your Tower instance. The Dataset should be created and an rnaseq pipeline running using the Dataset as itsinputparameter.
Congratulations! Your automation solution is complete and ready to process real events from your S3 Bucket.
Conclusion
Robust automation is a hallmark of quality production systems. This blog relied on AWS services to do much of the heavy lifting. At Seqera, we are committed to reducing the burden of production with Tower through deeper data source integrations and event-based systems. If you would like to learn more about how Nextflow and Tower can support your work, please reach out to us and we would be happy to discuss your needs.