
Versionable input data sources for Nextflow pipelines
We’re excited to announce Nextflow Tower Datasets! By giving users the ability to import and store their own input datasets in Tower, we are making it even easier to find and provide the correct data for any given workflow.
Tower Datasets includes full API compatibility, providing the ability to export and upload sample sheets from existing tools in standard formats including CSV and TSV.
Let’s get into the details.
Tower Datasets
Tower makes it trivial to execute and manage Nextflow workflows that require accessing large sets of input data. Besides execution, data provenance is vital for reproducibility in any data analysis context. We realised the importance of providing users with the ability to track, customise and version control their input data sources as well as workflow executions.
Tower Datasets is our first offering at bridging this gap. It provides the ability to drag and drop structured data such as sample sheets into the Tower UI, and provides details such as naming and descriptions. Each dataset can be version controlled allowing users to trace which workflow(s) were executed with which dataset.
Making data findable
Nextflow offers seamless integration with many different protocols out-of-the box. This means data can be located across a multitude of storage solutions including object buckets (s3, gs, az), shared file systems, SQL databases or public dataset repositories. Finding the exact path or location of input data can be a major challenge, especially for non-technical users. With Tower Datasets, sample sheets and other structured data types can now be imported or pre-populated into a workspace. This substantially reduces user-error and makes it simple to find data for a given experiment.
Right data for the right pipeline
Another common challenge is validation of the data. Kicking off a pipeline and returning the next day to a failed run is painful. We wanted to solve this problem and turned to the community for inspiration.
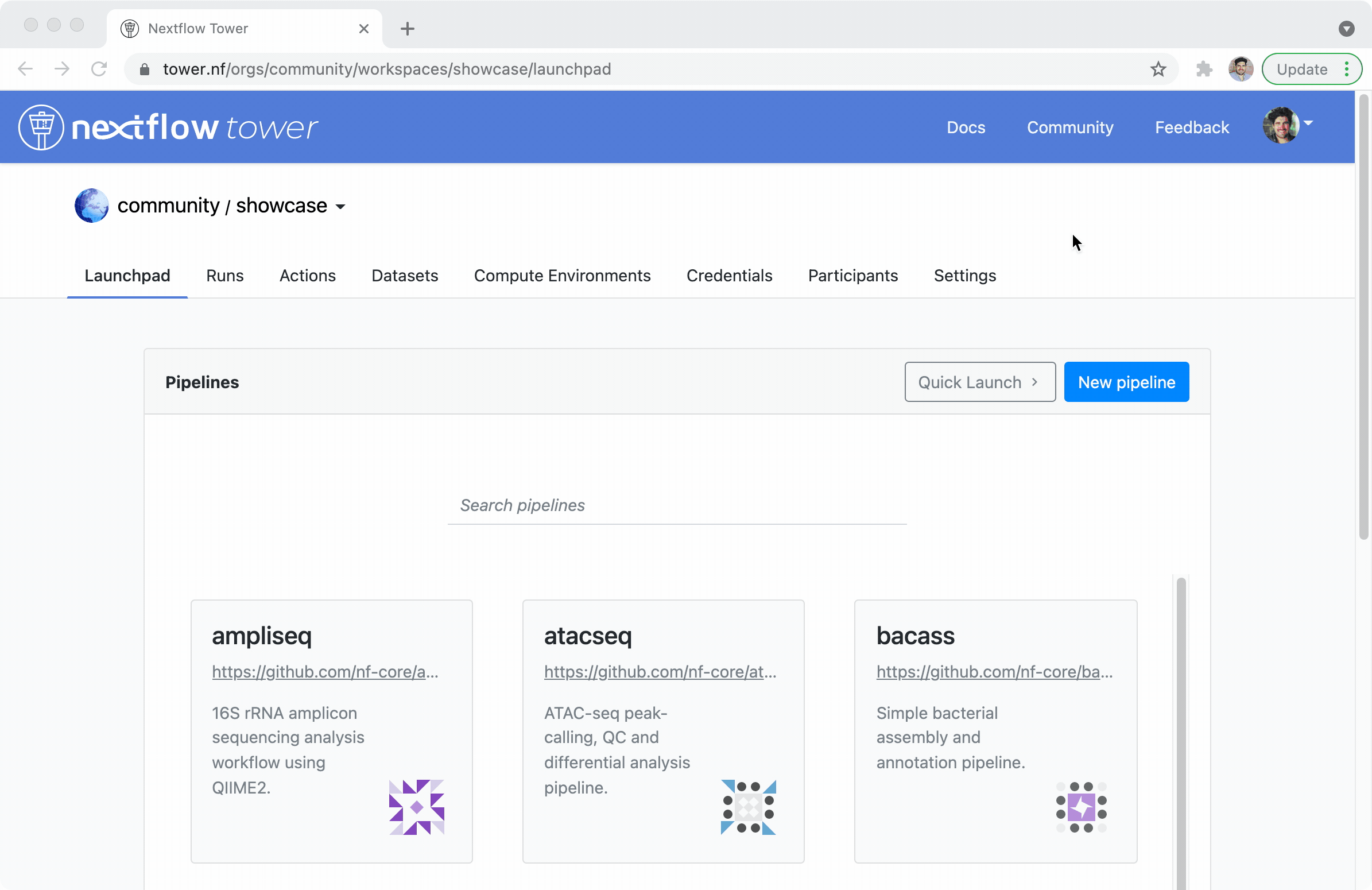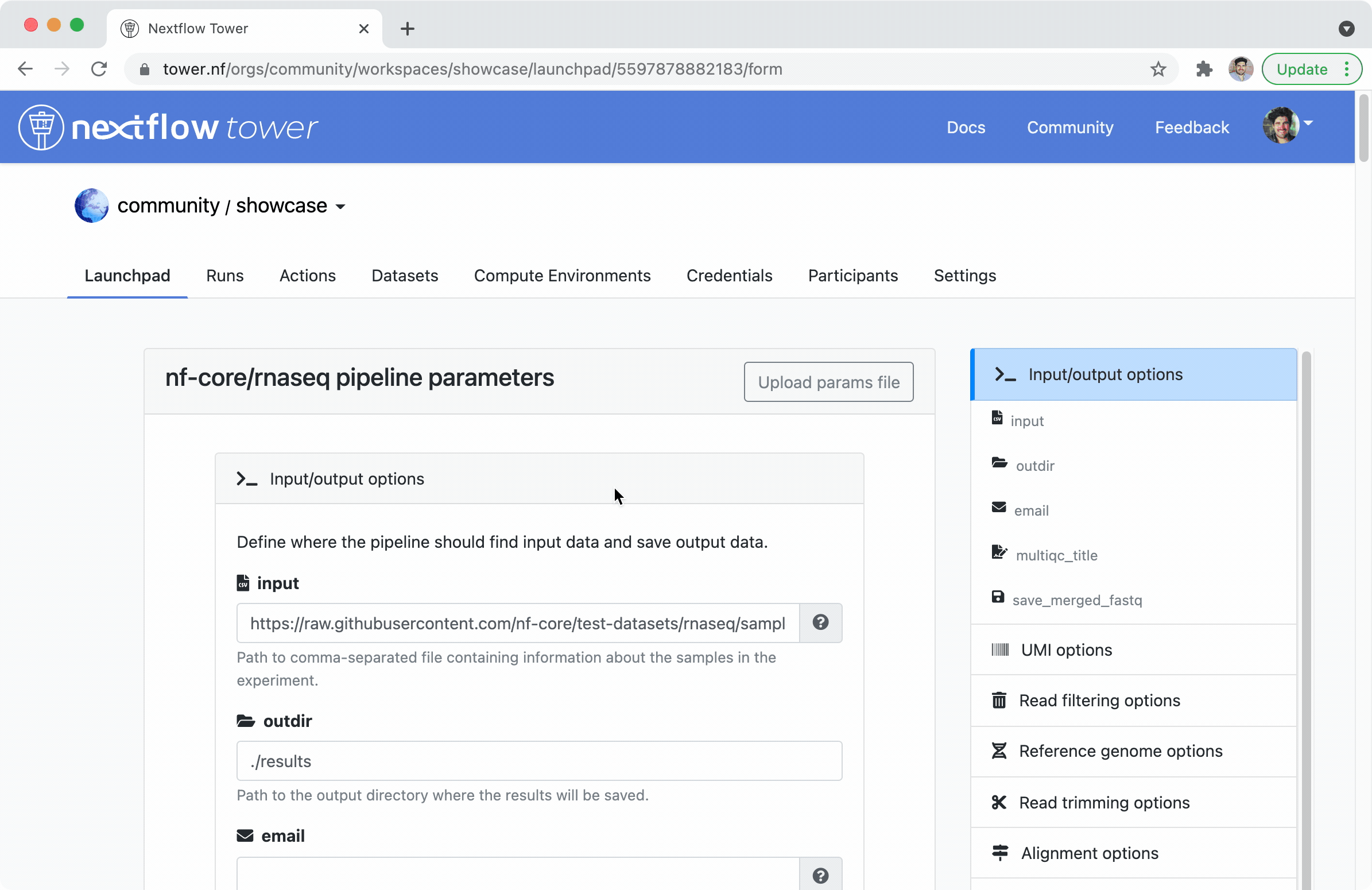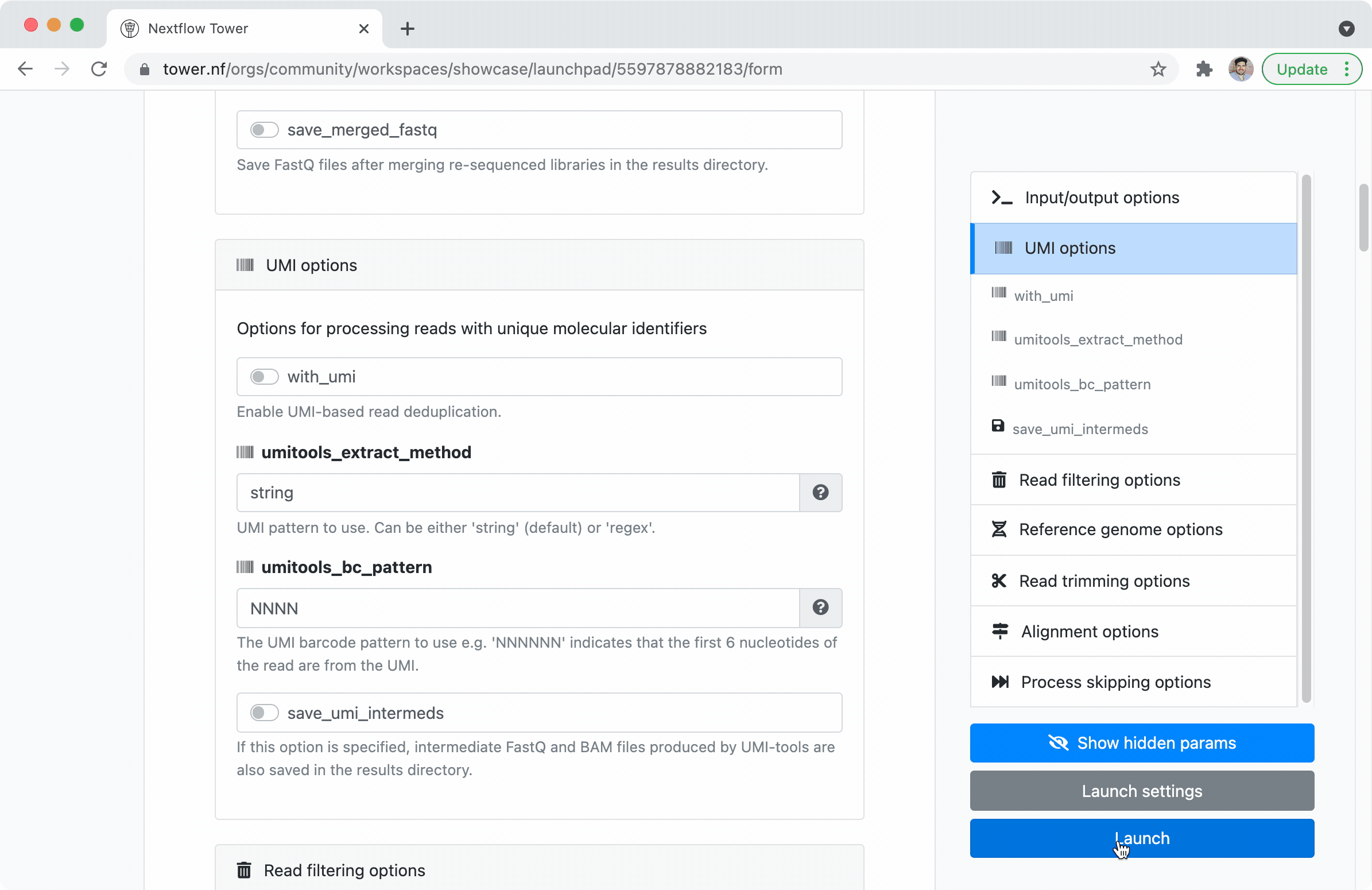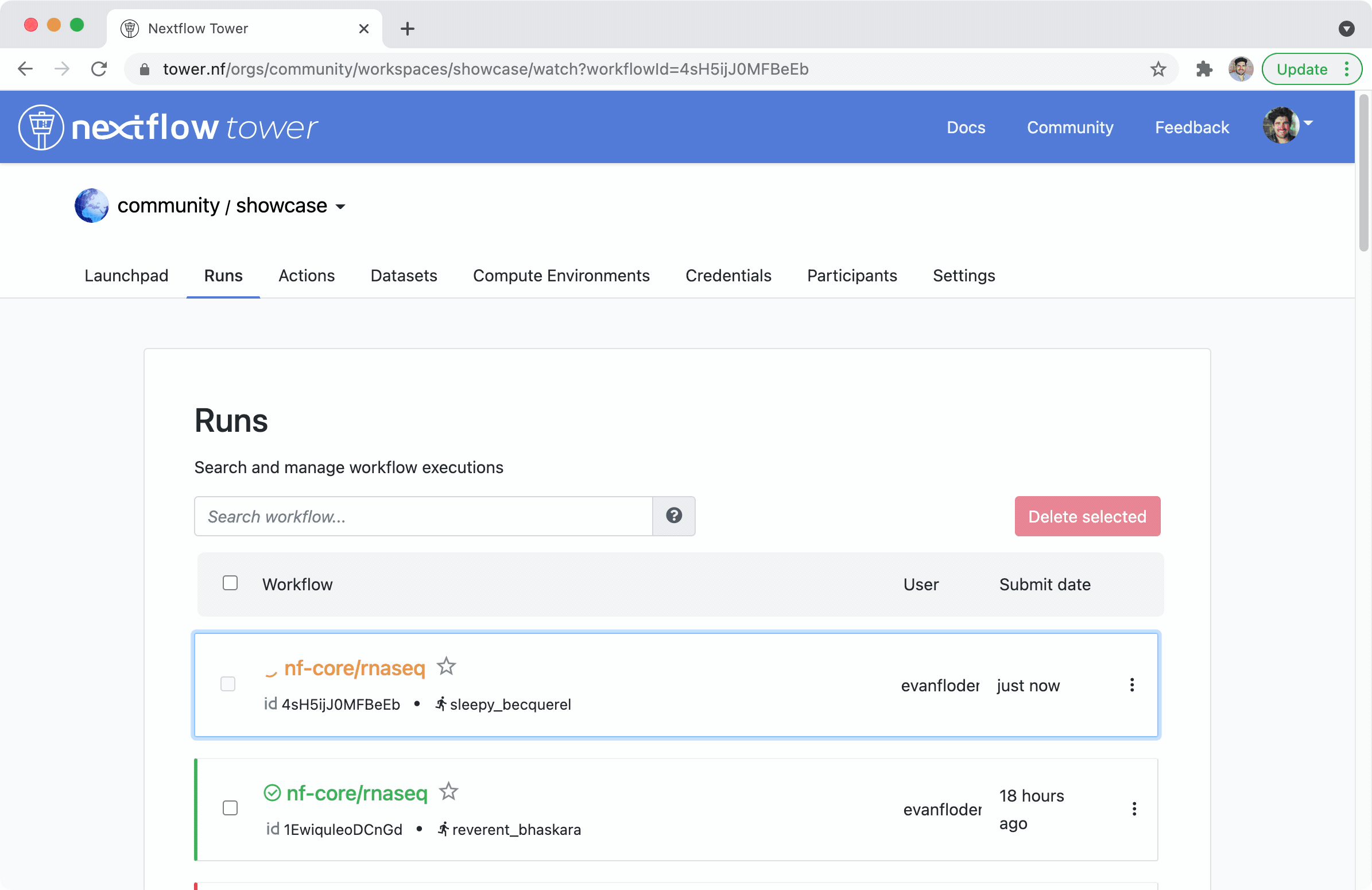
Since introducing Tower Launchpad, users can easily change pipeline parameters through a fully-customizable UI. This was made possible and is rendered by parsing the standardised Nextflow parameter schema file introduced by the nf-core community, e.g, nf-core/rnaseq. By extending this idea, the requirements and format of the input dataset can now also be encoded in a schema file, e.g., nf-core/rnaseq.
This means that Tower Datasets are automatically validated against the schema to dynamically allow users to select the appropriate dataset for any given pipeline execution. In a nutshell, only valid datasets for a pipeline input are exposed to the user.
What else can we build with Tower Datasets?
Tower Datasets was initially designed to store sample information analogous to a typical samplesheet in CSV/TSV format, but we are excited to hear what users build and the other requirements they have. The plan is to extend these capabilities to dynamically create and populate datasets with other file formats. We will also provide users with a more interactive search functionality in the Tower UI and add Tower Actions triggers to allow for automations using Datasets. Watch this space!
Accessing Tower Datasets
The datasets feature is available now over at the hosted version of Nextflow Tower. It will be rolled out shortly into the next Tower Enterprise release for our customers. If you have any questions, want to see a demo or just want to chat about your pipeline needs, head over to our contact page and we will be happy to set something up.
Credits
Thanks to the amazing Seqera team, the incredible nf-core crew and the Nextflow community for their fantastic support and dedication to this feature. It is an honor and a privilege to be able to collaborate with like-minded folks who are making it easier every day to execute analysis workloads!