
Container provisioning, cloud resource optimization, Google Cloud Batch support, and more in Tower Enterprise 22.3
Nextflow Tower Enterprise version 22.3 brings a host of new features, services, and improved cloud provider support.
Google Cloud Batch support
Adding to the variety of HPC schedulers and major cloud providers already supported by Tower, you can now create a compute environment for Google Cloud Batch. We endeavor to support new services as they emerge, enabling Nextflow and Tower users to take advantage of the latest technology to deploy pipelines in the environments that best fit their requirements.
Google Cloud Batch is a comprehensive cloud service suitable for multiple use cases, including HPC, AI/ML, and data processing. While it is similar to the Google Cloud Life Sciences API, used by many Tower users today, Google Cloud Batch offers a broader set of capabilities. As with Life Sciences, Google Cloud Batch automatically provisions resources, manages capacity, and allows batch workloads to run at scale. It also offers several advantages, including:
- →The ability to re-use VMs across job steps to reduce overhead and boost performance
- →Granular control over task execution, compute, and storage resources
- →Infrastructure, application, and task-level logging
- →Improved task parallelization, including support for multi-node MPI jobs, array jobs, and subtasks
- →Improved support for spot instances, which provide significant cost savings compared to regular instances
- →Streamlined data handling and provisioning.
A feature of Google Cloud Batch API that works well with Nextflow and Tower is its built-in support for data ingestion from Google Cloud Storage buckets. A Batch job can mount a storage bucket and make it directly accessible to a container running a Nextflow task. This feature makes data ingestion and sharing resulting data more efficient and reliable.
This is a Beta Tower feature — more capability will be added as Nextflow Google Cloud Batch support evolves.
Resource labels
Tower now offers a flexible annotation and tracking system for the cloud resources generated by a run, in the form of resource labels. Workspace admins and owners can assign resource labels to cloud compute environments in Tower. These propagate to the resources in question on the cloud provider’s platform (in the form of AWS resource tags, Google Cloud resource tags, etc.), allowing you to keep track of usage. When you generate the compute environment with Forge, all resources generated at creation time are tagged; if the CE is not forged by Tower, resource labels are applied during workflow submission and execution.
Dashboard
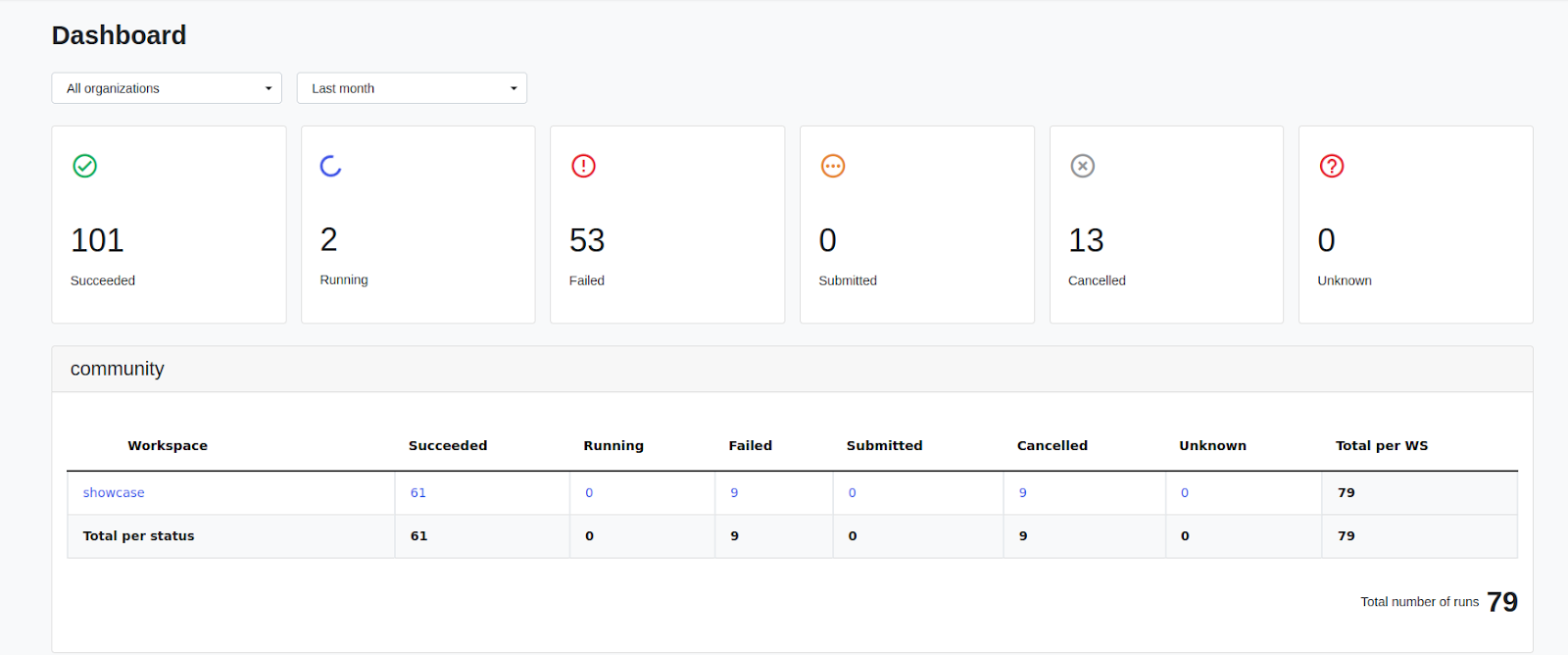
Tower 22.3 introduces a dashboard interface to view total runs and run status, filtered by organization or user workspace. This facilitates overall run status monitoring and early detection of execution issues.
Admin panel enhancements
We’ve added new user and organization management features to the Tower admin panel.
Admins can now view all users, assign or remove users, and change user roles within an organization — all from the Users tab. Similarly, admins can view organizations, assign or remove users, and manage the user roles within an organization from the Organizations tab.
This provides insight at a glance and enhances admins’ control over users and organizations, from a single view in Tower.
Resource optimization (technology preview)
Cloud resource optimization is a significant challenge in running cost-efficient production pipelines. Allocating resources based on coded predictions in pre-existing pipelines is often inaccurate as pipelines are stress-tested with large datasets. This does not account for the differing data requirements of each use case. Moreover, manually analyzing hundreds or thousands of pipeline tasks individually to allocate appropriate resources is a mammoth task that few have the time and inclination to undertake. If ever there was a case for automation, this is it.
Tower Cloud now offers cloud resource optimization when running pipelines. Using the extensive resource usage data which Tower already collects for each pipeline run, a set of per-process resource recommendations is generated that can be applied to subsequent runs. This feature is geared to optimize resource use significantly, while being conservative enough to ensure that pipelines run reliably. This is an exciting Tower innovation that can lead to dramatic efficiency gains in the cloud.
Resource optimization is currently only available on Tower Cloud (tower.nf). For more information about this optional feature, contact us.
Wave containers (technology preview)
Containers have become an essential part of well-structured data analysis pipelines. They encapsulate applications and dependencies in portable, self-contained packages that can be easily distributed — key to enabling reproducible results.
Today, we face new challenges as the need for portability of increasingly complex data pipelines leads to workflows that often consist of dozens of discrete container images. Pipeline developers must manage and maintain these containers and ensure that their functionality precisely aligns with the requirements of every pipeline task. This leads to more time spent on maintaining infrastructure and less time actually running pipelines.
To help manage the complexity and tedium of these container requirements, Nextflow has introduced the Wave container provisioning and augmentation service. This is a fundamental game changer for deploying and managing containers in Nextflow.
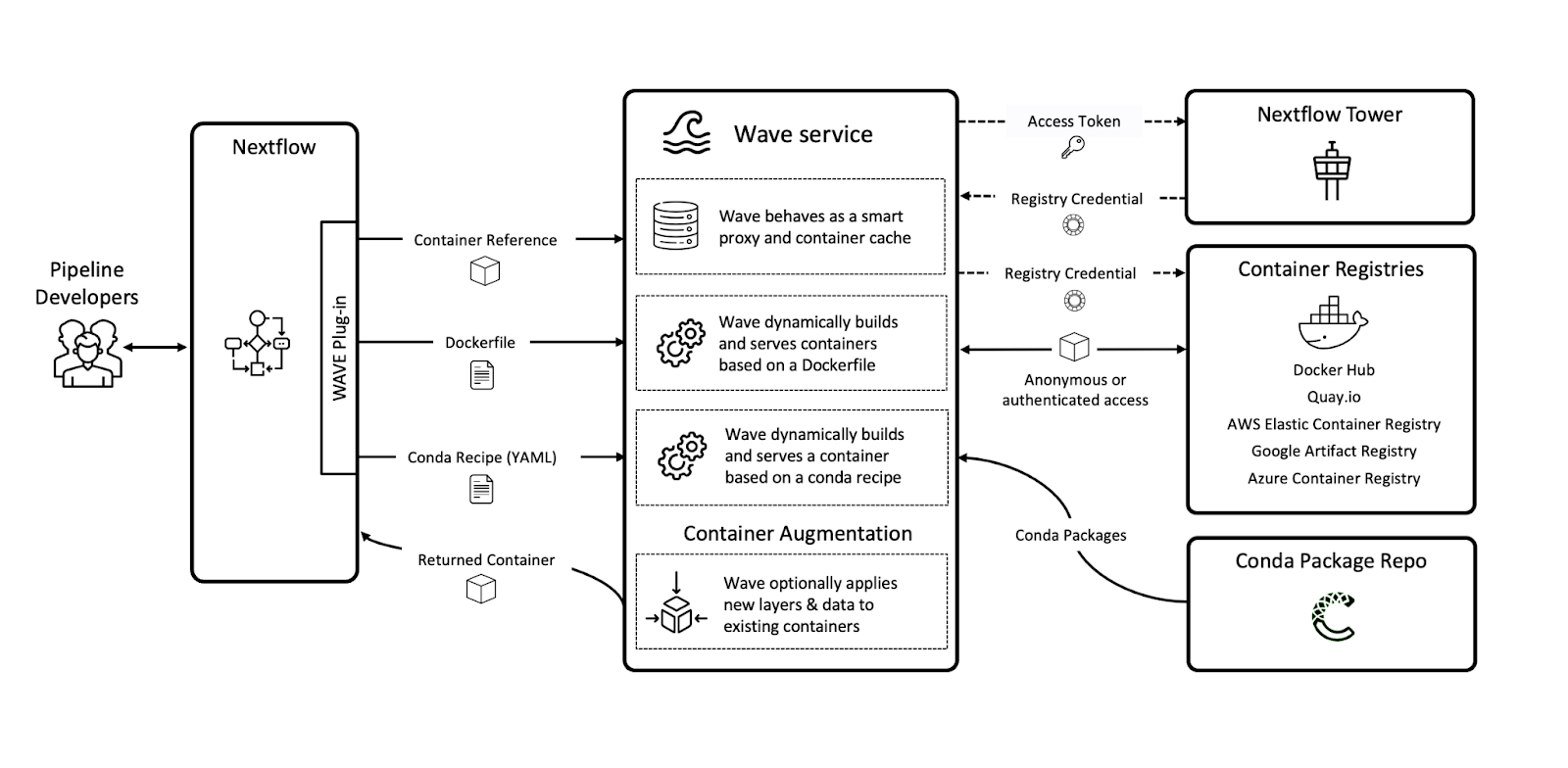
When a pipeline is run in Nextflow using Wave, the Wave service uses a Dockerfile stored in the process directory to build a container in the target registry. When the container is returned, the Wave service can add functional layers and data on the fly before it is used in Nextflow for actual process execution.
Wave also enables the use of private container registries in Nextflow — registry credentials stored in Tower are used to authenticate to private container registries with the Wave service.
The Wave container provisioning service is available free of charge as a technology preview to all Nextflow and Tower users. During the preview period, anonymous users can build up to 10 container images per day and pull 100 containers per hour. Tower authenticated users can build 100 container images per hour and pull 1000 containers per minute. After the preview period, we plan to make the Wave service available free of charge to academic users and open-source software (OSS) projects.
See here for an introductory overview of Wave containers on the Nextflow blog, and here for a live demo and introduction of Wave from the Nextflow 2022 Summit, by Seqera co-founder and CTO Paolo di Tommaso.
This feature is currently only available on Tower Cloud (tower.nf). For more information about this optional feature, contact us.
Fusion file system (technology preview)
The implementation of Wave containers also provides the ability to package a Fusion file system client to be used by Nextflow pipelines.
Fusion is a virtual distributed file system which allows data hosted in AWS S3 buckets to be accessed directly by the file system interface used by pipeline tools. This means that Nextflow pipelines can use an S3 bucket as the work directory and pipeline tasks can access the S3 bucket natively as a local file system path.
Importantly, this eliminates the additional step of copying files in and out of object storage. Fusion file system takes advantage of Nextflow’s task segregation and idempotent execution model to optimize and speed up file access operations.
Fusion, as used by the Wave containers service, is available free of charge as a technology preview to all Nextflow and Tower users. After the preview period, we plan to make the service available free of charge to academic users and open-source software (OSS) projects.
This feature is currently only available on Tower Cloud (tower.nf). For more information about this optional feature, contact us.
Other enhancements
In addition to the big ticket features above, version 22.3 also introduces a long list of smaller features, incremental improvements, and bug fixes. See the full list in our release notes.
Tower 22.3 further advances our goal of maximizing your productivity by enabling collaborative data analysis at scale — on-prem or in the cloud.